VMware недавно опубликовала обновлённый набор технических руководств, которые приводят рекомендации в соответствие с архитектурой эпохи VMware Cloud Foundation
и с новыми возможностями приложений Microsoft, включая SQL Server 2025 и Windows Server 2025.
Если вы планируете развёртывание VCF, модернизируете существующие среды, стандартизируете платформу, обновляете парк SQL Server или модернизируете инфраструктуру идентификации, мы рекомендуем ознакомиться с этими документами до того, как будет окончательно утверждён ваш следующий дизайн-воркшоп, цикл закупок или план миграции.
Руководство 1: Проектирование Microsoft SQL Server на VMware Cloud Foundation
Для многих команд решение о виртуализации SQL Server уже принято. Как говорится в руководстве: «вопрос больше не в том, виртуализировать ли SQL Server, а в том, как…». И это «как» существенно изменилось в мире VCF. Платформа стала более регламентированной, операционная модель — более стандартизированной, а поддерживающие возможности (хранилище, сеть, управление жизненным циклом, безопасность) эволюционировали с учётом развития аппаратных возможностей и операционных методик.
Обновлённое руководство предназначено для читателей, которые уже понимают как VCF, так и SQL Server. Оно ориентировано на несколько ролей: архитекторов, инженеров/администраторов и DBA.
Несколько моментов, на которые стоит обратить внимание:
Современные рекомендации по CPU и NUMA теперь учитывают и новое поведение топологии в эпоху VCF. Руководство рассматривает «новые параметры конфигурации топологии vNUMA в VMware Cloud Foundation (VCF)» и объясняет, почему это поведение важно для крупных виртуальных машин SQL Server.
Чёткая и обновлённая позиция по CPU hot plug в эпоху SQL Server 2025. В руководстве прямо указано: CPU Hot-Add больше не поддерживается в SQL Server 2025, и его не следует включать на таких виртуальных машинах.
Рекомендации по хранилищу, соответствующие направлению развития VCF. Если вы оцениваете архитектурные варианты vSAN, руководство объясняет, почему vSAN Express Storage Architecture (ESA) привлекателен для заказчиков, переходящих на более современное оборудование, и подчёркивает возможности эффективности ESA, такие как глобальная дедупликация и преимущества сжатия для нагрузок баз данных.
Пояснения по устаревающим функциям, влияющим на долгоживущие архитектуры. Если в вашей текущей архитектуре активно используются vVols, учтите, что Virtual Volumes объявлены устаревшими, начиная с VCF 9.0 и VMware vSphere Foundation 9.0 (полный отказ запланирован в будущих релизах).
Операционная реалистичность для мобильности и обслуживания. Руководство рассматривает использование multi-NIC vMotion для снижения риска зависания (stun) при миграции крупных, потребляющих много памяти виртуальных машин SQL, а также отмечает, что VCF внедряет vMotion Notifications, чтобы помочь чувствительным к задержкам и кластер-осведомлённым приложениям безопаснее обрабатывать миграции.
Если вы принимаете решения - это тот документ, который снижает объём переработок, вызванных неожиданностями. Если вы технический специалист - это тот документ, который не позволит вам унаследовать архитектуру в стиле «it depends», которая позже приведёт к простою.
Руководство 2: Проектирование Microsoft SQL Server для высокой доступности на VMware Cloud Foundation
Второе руководство сосредоточено там, где ставки особенно высоки: корректное проектирование доступности SQL Server на VCF без смешивания устаревших предположений, неподдерживаемых конфигураций или подхода «потом исправим» в кластеризации.
Оно написано для смешанной аудитории, включая DBA, администраторов VMware, архитекторов и IT-руководителей. И в нём ясно указано, что «доступность» — это не функция, которую добавляют в конце; выбранная модель защиты должна определяться бизнес-требованиями.
Несколько особенно практичных обновлений:
Реалии доступности SQL Server 2025, чётко сопоставленные с механизмами защиты. Руководство связывает уровни защиты с современными возможностями обеспечения доступности SQL Server, подчёркивает области, где SQL Server 2025 усиливает архитектуры на базе Availability Groups (AG), и отмечает, что Database Mirroring удалён в SQL Server 2025.
Рекомендации по согласованию жизненного цикла, которые действительно важны для IT-руководства. Начиная с SQL Server 2025, отмечается, что более старые версии Windows Server вышли из основной поддержки, и рекомендуется использовать Windows Server 2025 или Windows Server 2022 при наличии совместимости — прямой переход к поддерживаемым и обоснованным платформам.
Современные варианты кластеризации с общими дисками без навязывания устаревших архитектур. Руководство указывает, что в средах эпохи VCF 9 семантика общих дисков для FCI может быть реализована современными способами — подчёркивается использование Clustered VMDKs и явно обозначается движение в сторону отказа от устаревших зависимостей.
Рекомендации по DRS anti-affinity, предотвращающие «самоорганизованные» события HA. Если узлы кластера SQL работают на одном и том же хосте ESXi «потому что так решил DRS», это не высокая доступность, а отложенный инцидент. Настройте соответствующие правила DRS, чтобы узлы кластера были физически разделены.
Требования к vMotion Application Notification, изложенные подробно. Руководство описывает использование уведомлений приложений, включая требования, такие как актуальные VMware Tools и рекомендуемая настройка таймаутов — именно те детали, которые команды часто выясняют в условиях уже упавшей системы.
Рекомендации по vSAN ESA, отражающие текущие возможности. Указывается направление политик ESA и отмечается глобальная дедупликация (впервые представленная в VCF 9.0) как рекомендуемая для определённых сценариев Availability Group SQL Server в пределах одного кластера vSAN.
Это то руководство, которое вы передаёте команде, когда бизнес говорит: «нам нужна более высокая доступность», — и вы хотите, чтобы ответом стало инженерно проработанное решение.
Руководство 3: Виртуализация служб домена Active Directory на VMware Cloud Foundation
Active Directory (AD) Domain Services (DS) — одна из тех служб, о которых не думают до тех пор, пока всё не перестанет работать. Обновлённое руководство по AD DS прямо признаёт это, указывая, что многие организации справедливо рассматривают AD DS как по-настоящему критичное для бизнеса приложение, поскольку аутентификация, доступ к ресурсам и бесчисленные рабочие процессы зависят от него.
Оно также напрямую обращается к сохраняющемуся рефлексу «физического контроллера домена». Благодаря развитию Windows Server и зрелым практикам VCF, в руководстве говорится, что эти улучшения теперь позволяют организациям «безопасно виртуализировать сто процентов своей инфраструктуры AD DS».
Существенно обновлены не общие рекомендации «виртуализируйте это», а современный набор функций и механизмов защиты, которые меняют подход к проектированию и защите виртуальных контроллеров домена:
В руководстве указано, что лишь несколько усовершенствований существенно изменяют прежние рекомендации, включая Virtualization-Based Security (VBS), Secure Boot, шифрование на уровне виртуальной машины и улучшенную синхронизацию времени в гостевых ВМ — и эти изменения учтены там, где это необходимо.
Документ явно ориентирован на несколько аудиторий (архитекторов, инженеров/администраторов и руководителей/владельцев процессов), что важно для AD DS, поскольку проектирование и эксплуатация неразделимы.
Подчёркиваются операционные меры защиты при восстановлении после сбоев. Например, рекомендуется использовать приоритет перезапуска ВМ в vSphere HA, чтобы ключевые инфраструктурные службы запускались раньше после аварийного восстановления.
Подробно рассматриваются механизмы обеспечения целостности в эпоху виртуализации (например, поведение VM-Generation ID), созданные специально для устранения исторических опасений, связанных со снапшотами и откатами.
Если вы модернизируете инфраструктуру идентификации, консолидируете датацентры или строите частное облако на базе VCF с сильной позицией по безопасности, этот документ обязателен к прочтению. AD DS — это не просто ещё одна рабочая нагрузка. Это сущность, от которой зависит работа всего вашего стека.
Руководство 4: Запуск Microsoft SQL Server Failover Cluster Instance на VMware vSAN платформы VMware Cloud Foundation 9
Если ваша модель обеспечения доступности по-прежнему основана на кластеризации с общими дисками — будь то из-за ограничений приложений, операционных предпочтений или необходимости сохранить модель SQL Server FCI — это руководство является практическим дополнением «как это реально работает на VCF 9» к более общим рекомендациям по HA. Это эталонная архитектура для запуска Microsoft SQL Server Failover Cluster Instance (FCI) с использованием общих дисков на базе vSAN, валидированная как для стандартного кластера vSAN, так и для сценария растянутого кластера vSAN.
Несколько моментов, на которые стоит обратить внимание:
Нативная поддержка WSFC + общих дисков на vSAN (с подробным описанием механики). В VCF 9 «vSAN обеспечивает нативную поддержку виртуализированных Windows Server Failover Clusters (WSFC)» и «поддерживает SCSI-3 Persistent Reservations (SCSI3PR) на уровне виртуального диска» — ключевое требование для арбитража общих дисков в WSFC.
Две настройки конфигурации, от которых зависит работоспособность общих дисков. Указывается, что общие диски должны быть подключены к контроллеру с параметром SCSI Bus Sharing, установленным в Physical, и что «режим диска для всех дисков в кластере должен быть установлен в Independent – Persistent», чтобы избежать неподдерживаемой семантики снапшотов на общих дисках.
Операционные особенности растянутого кластера: задержки, размещение и кворум являются частью архитектуры. Рекомендуется «менее четырёх миллисекунд межсайтовой (round trip) задержки» для SQL-баз данных уровня tier-1 в растянутых кластерах vSAN, а также подчёркивается необходимость правил DRS VM/Host для разделения узлов WSFC по разным хостам.
Также рекомендуется использовать диск-свидетель кворума, чтобы растянутый кластер сохранял доступность witness-диска при отказе сайта без остановки службы кластера FCI.
Практический путь миграции с SAN pRDM на общие VMDK vSAN. С самого начала подчёркивается: «перед миграцией настоятельно рекомендуется создать резервную копию», и отмечается, что миграция выполняется офлайн. Описываются шаги по остановке роли кластера, выключению узлов и использованию Storage Migration для преобразования pRDM в VMDK на vSAN ± с обходным решением через PowerCLI (включая пример кода) в случае, если выбор формата диска в мастере Migrate недоступен.
Это руководство, которое вы передаёте команде, когда требование звучит как «нам нужна семантика FCI», и вы хотите получить осознанную, поддерживаемую архитектуру.
Что дальше
Если вы активно проектируете, обновляете или мигрируете инфраструктуру, рассматривайте эти руководства в контексте команд:
Команды платформы: сначала прочитайте руководство по SQL Server, чтобы согласовать значения по умолчанию вычислений/хранилища/сети с поведением SQL.
DBA и инженеры инфраструктуры: прочитайте руководство по HA до того, как зафиксируете модель кластеризации, стратегию хранения и модель обслуживания.
Команды по идентификации и безопасности: прочитайте руководство по AD DS, чтобы согласовать меры настройки, восстановления и операционные процессы с современными механизмами защиты виртуализации.
Команды, использующие (или стандартизирующие) SQL Server FCI: прочитайте руководство по FCI на vSAN, чтобы зафиксировать требования к общим дискам, позицию по политике хранения и ограничения растянутого кластера до внедрения.
Ниже приведены прямые ссылки для скачивания упомянутых документов:
Недавно был выпущен пакет управления vCommunity Management Pack для VCF Operations (подробнее о нем - тут), который охватывает несколько сценариев использования, включая: расширенные системные настройки хоста ESX, его пакеты и лицензирование, статус сетевых интерфейсов (NIC), расширенные параметры виртуальных машин, параметры ВМ, типы контроллеров SCSI виртуальных машин, а также службы события Windows.
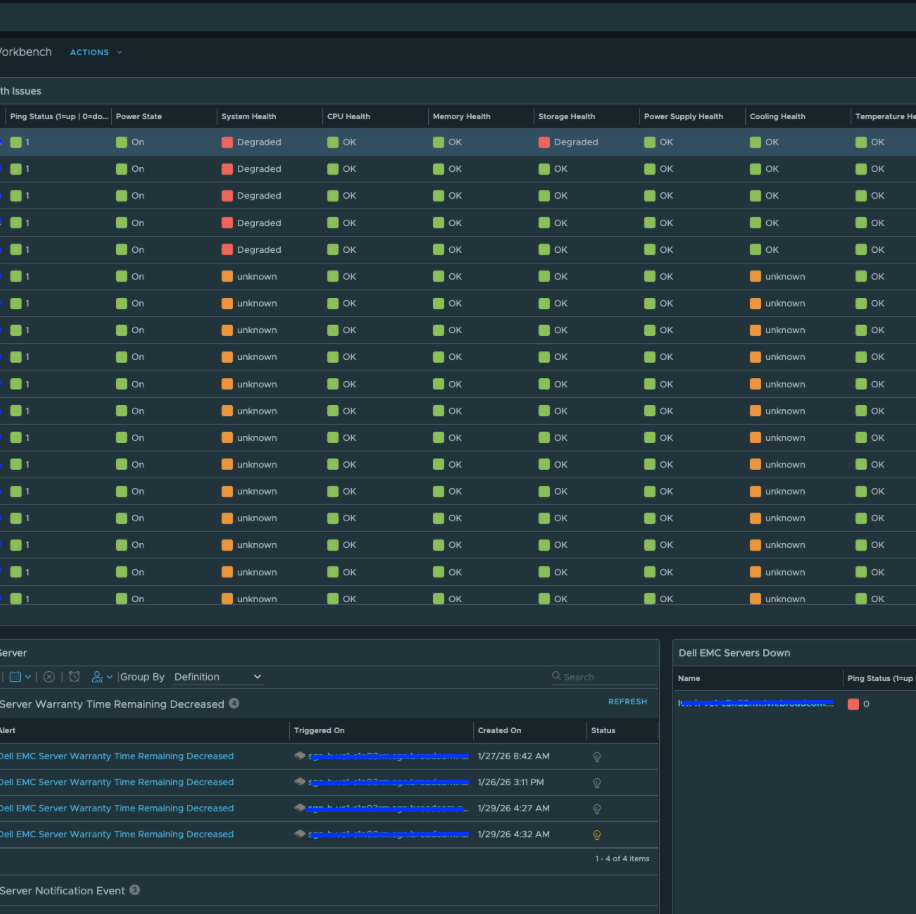
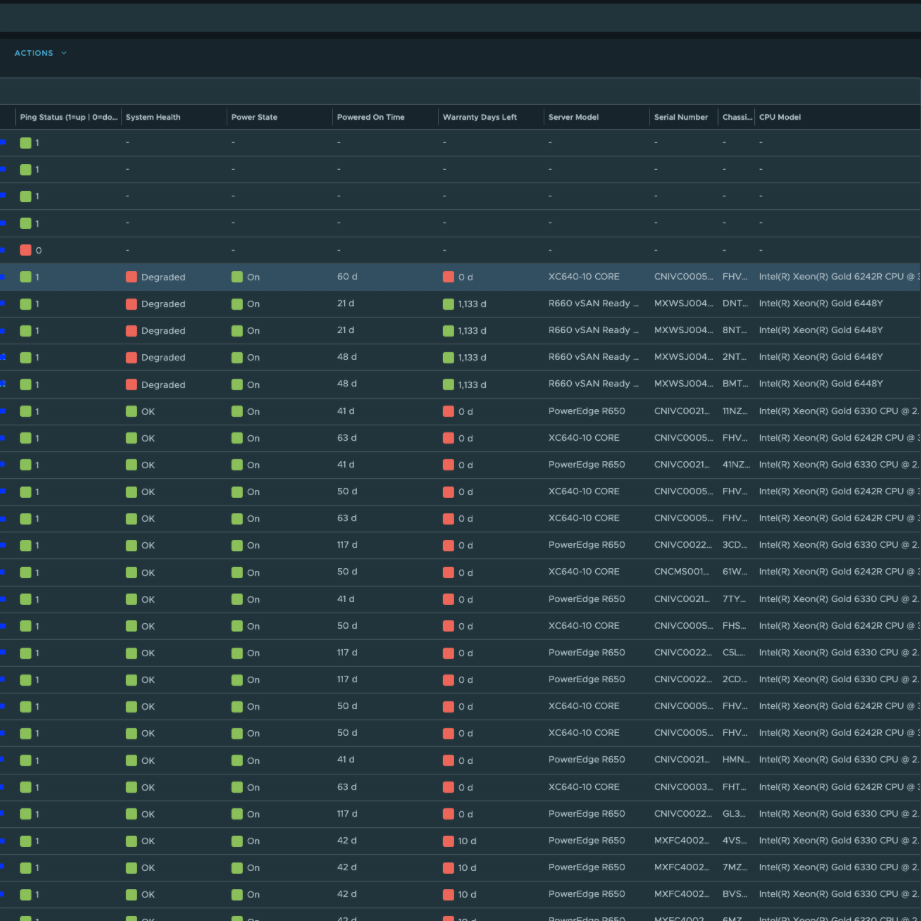
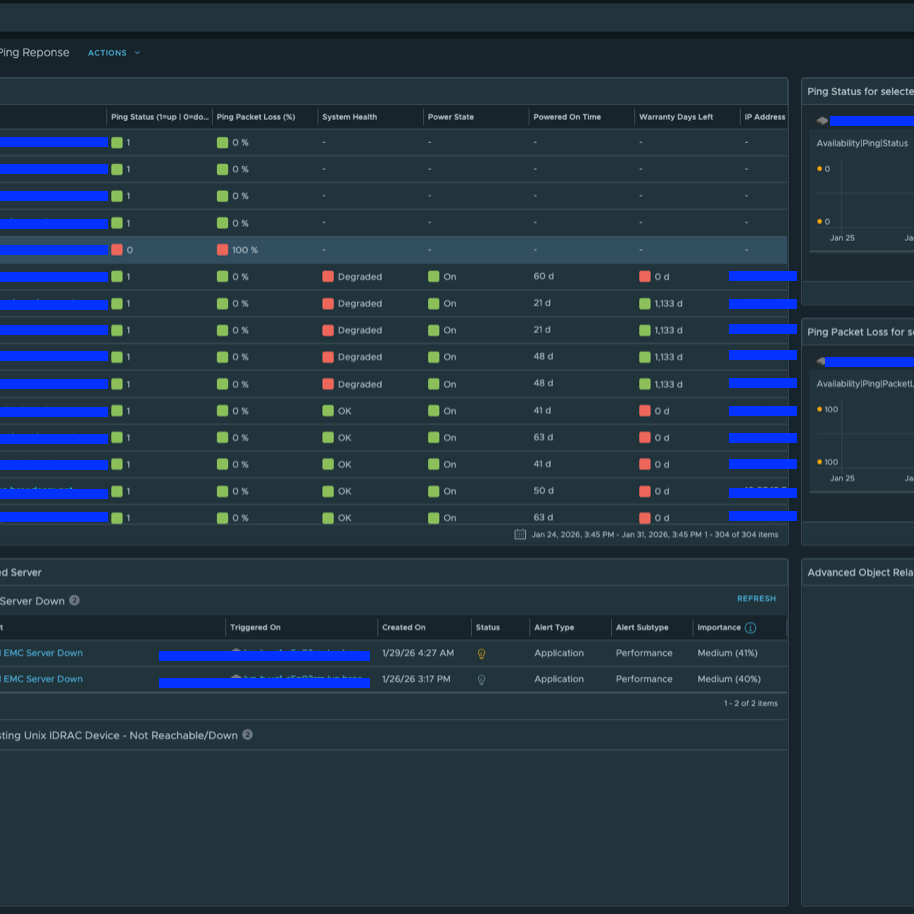
Ну а на днях стал доступен для скачивания проект Hardware vCommunity Management Pack для VCF Operations, разрабатываемый инженером Broadcom Онуром Ювсевеном. Начальная версия поддерживает серверы Dell EMC PowerEdge (с использованием Redfish API на iDRAC). Он собирает десятки метрик, свойств и событий. Пакет управления включает 5 дашбордов, 8 представлений, 14 алертов и 19 симптомов (symptoms). Дашборды выглядят следующим образом.
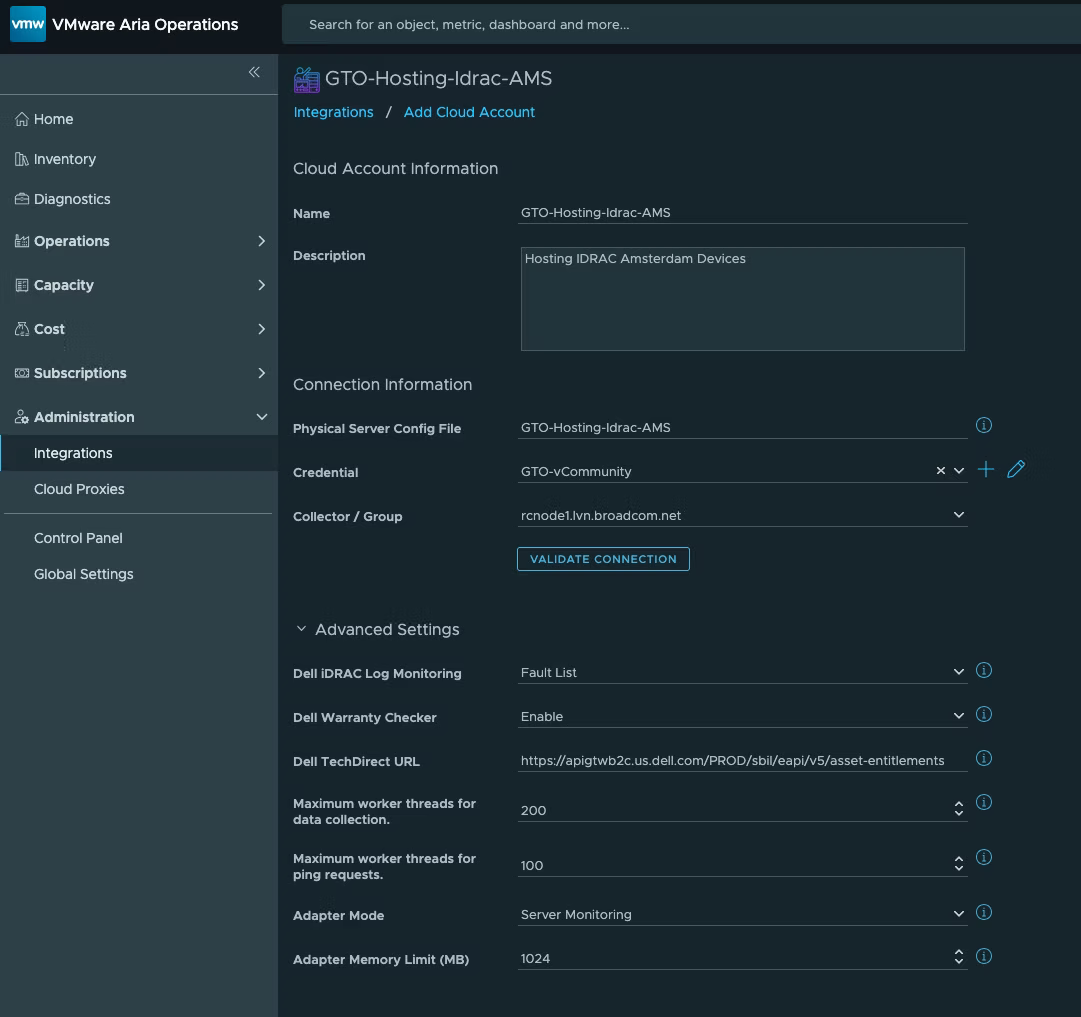
Сам Management Pack можно скачать здесь. После загрузки он устанавливается так же, как и любой другой Management Pack. Затем необходимо создать экземпляр адаптера (или несколько, если требуется), который будет выглядеть примерно следующим образом.
Существует несколько требований:
Файл конфигурации физических серверов — список FQDN/IP-адресов серверов Dell EMC. Файлы конфигурации можно создать в разделе Operations > Configurations > Management Pack Configurations > User Defined. Формат должен быть вот таким.
Учётные данные iDRAC Redfish API (только чтение), а также Dell TechDirect Client ID/Secret (если требуется информация о гарантии).
Collector/Group — необходимо использовать Cloud Proxy.
Dell iDRAC Log Monitoring — уровень событий iDRAC, которые вы хотите собирать (или Disabled, если сбор не нужен).
Dell TechDirect URL — URL Dell TechDirect, к которому экземпляр адаптера будет обращаться для получения информации о гарантии.
Maximum worker threads for data collection — максимальное количество рабочих потоков для сбора данных (по умолчанию 200).
Maximum worker threads for ping request — максимальное количество рабочих потоков для ping-запросов (по умолчанию 100).
Adapter Mode — режим работы адаптера: Server Monitoring или PING Only.
Adapter Memory Limit (MB) — максимальный объём памяти, который будет использовать экземпляр адаптера.
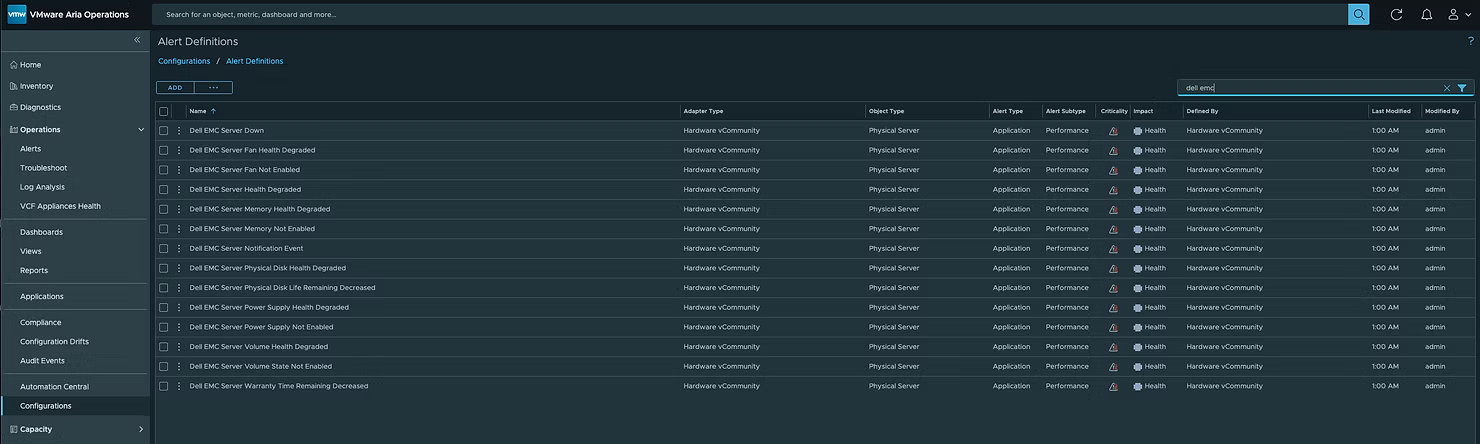
После установки назначьте Custom Group Dell EMC Servers политике Hardware vCommunity Policy. Это включит все определения оповещений. vCommunity Management Pack создаст новый тип объекта с именем Physical Server.
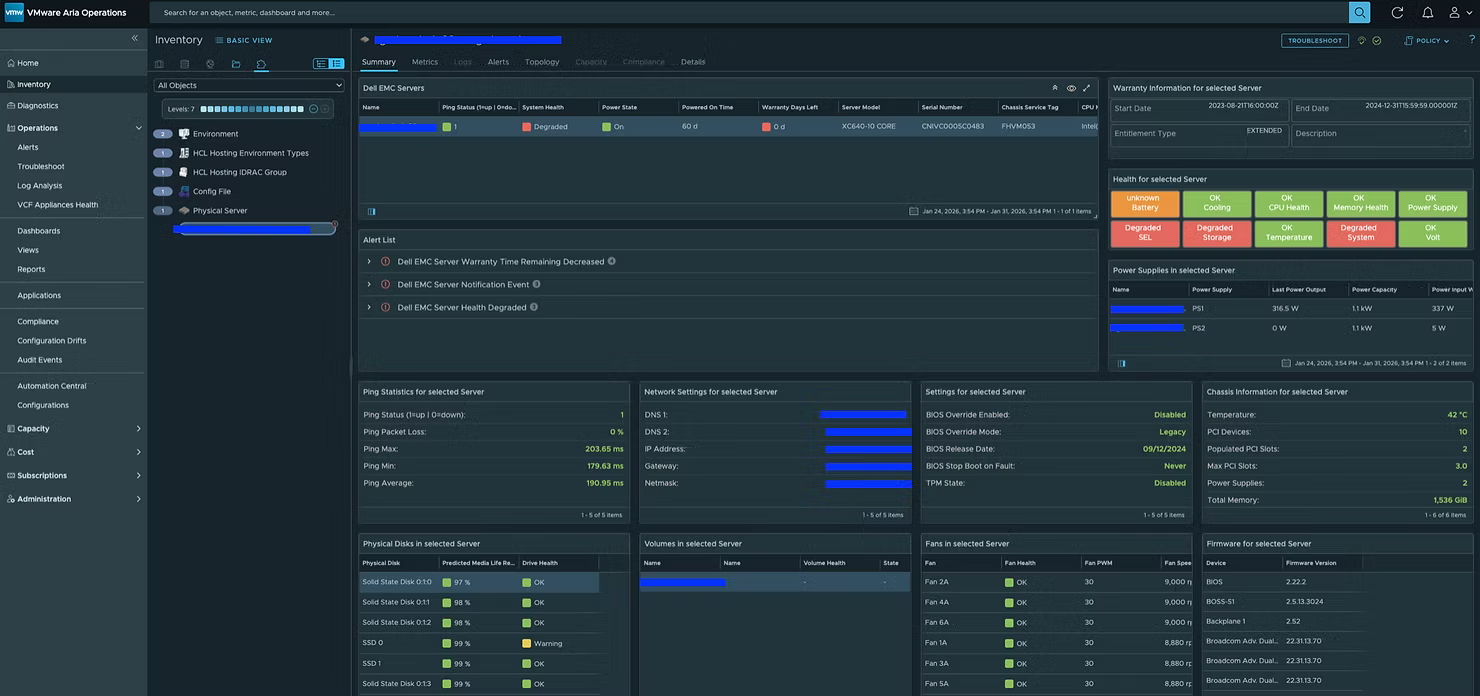
MP собирает десятки метрик и свойств не только по самому серверу, но также по батареям, блокам питания, вентиляторам и другим компонентам. Кроме того, был добавлен бонусный дашборд (Dell EMC Server Details), который при желании можно использовать в качестве страницы сводной информации по физическому серверу (Physical Server Summary Page).
Чтобы настроить этот дашборд как страницу сводки физического сервера, выполните описанные здесь действия. После настройки он будет выглядеть следующим образом.
vCommunity Hardware Management Pack также включает алерты, как показано ниже:
Два ключевых свойства, которые собираются и по которым формируются оповещения — это остаточный прогнозируемый срок службы физического диска (Physical Disk Predicted Media Life Remaining) и оставшийся срок гарантии (Warranty Remaining), что позволяет администраторам заблаговременно планировать обслуживание и предотвращать проблемы.
В дальнейшем планируется расширение функциональности, включая связи с хостами ESX и поддержку дополнительных аппаратных платформ. Скачивайте и начинайте использовать уже сегодня!
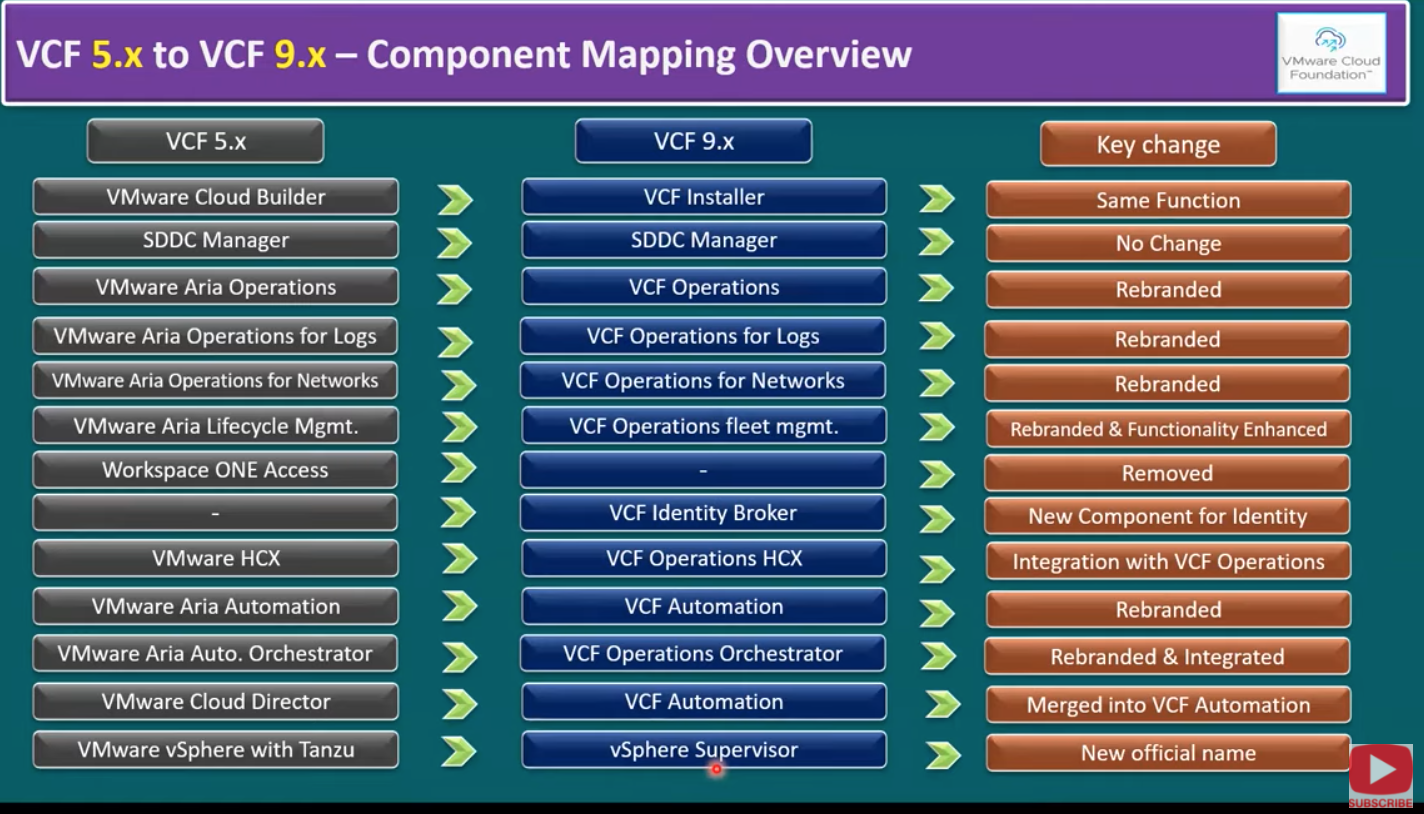
Переход на VMware Cloud Foundation (VCF) 9 — это не просто обновление версии платформы. Он включает ребрендинг ключевых сервисов, перенос функций между компонентами, а также существенные улучшения управления жизненным циклом (Lifecycle Management). Для команд, планирующих миграцию с VCF 5.x, важно понимать, что именно изменилось: какие элементы остались прежними, какие переименованы, а какие были полностью заменены.
Об этом в общих чертах мы писали в прошлой статье, а сегодня разберём переход с VCF 5.x серии на версию VCF 9 через призму:
Сравнения ключевых компонентов
Архитектурных изменений
Обновлений управления жизненным циклом
Замены компонентов и блоков функционала
Обо всем этом рассказывается в видео ниже:
Базовая архитектура управления: что осталось неизменным
SDDC Manager — ядро VCF остаётся тем же
Один из наиболее важных выводов: SDDC Manager по-прежнему остаётся центральным движком управления VCF, и он:
Присутствует как в VCF 5, так и в VCF 9
Не меняет название (нет ребрендинга)
Остаётся основным интерфейсом управления инфраструктурой
Однако отмечается, что в VCF 9 функциональность SDDC Manager расширена и улучшена по сравнению с 5-й серией.
Это важно, потому что SDDC Manager — "точка сборки" всей архитектуры VCF: он стабильный и развивается, миграции проще планировать и стандартизировать.
Изменения бренда и унификация: Aria -> VCF Operations
Одно из наиболее заметных изменений VCF 9 — это масштабный ребрендинг линейки VMware Aria в сторону единого зонтичного бренда VCF Operations.
VMware Aria Operations -> VCF Operations
Ранее компонент VMware Aria Operations выполнял роль:
Централизованных дашбордов
Мониторинга инфраструктуры
Уведомлений и alerting
SNMP-настроек
Кастомной отчётности (например, oversizing виртуальных машин)
Capacity planning
В VCF 9 этот же компонент переименован как часть стратегии VMware по движению к унифицированной "operations-платформе" в рамках VCF. Функционально компонент выполняет те же задачи, но позиционирование стало единым для всей платформы.
Operations-экосистема: логирование и сетевые инсайты
Aria Operations for Logs -> VCF Operations for Logs
Компонент логирования в VCF 5 назывался по-разному в средах заказчиков: Aria Operations for Logs и Log Insight. По сути — это централизованный syslog-агрегатор и анализатор, собирающий логи от всех компонентов VCF. В VCF 9 Aria Operations for Logs переименован VCF Operations for Logs. Функционально это тот же концепт, сбор логов остаётся централизованным и управляется как часть единого "Operations-стека".
Aria Operations for Network Insights -> VCF Operations for Network
Сетевой компонент прошёл длинный путь переименований: vRealize Network Insight, затем Aria Operations for Networks и, наконец, в VCF 9 он называется VCF Operations for Network.
Он обеспечивает:
Централизованный мониторинг сети
Диагностику
Анализ сетевого трафика
Возможности packet capture от источника до назначения
В VCF 5 жизненным циклом (апдейты/апгрейды) занимался компонент Aria Lifecycle Management (LCM), В VCF 9 сделан важный шаг - появился компонент VCF Operations Fleet Management. Это не просто переименование - продукт получил улучшенную функциональность, управление обновлениями и версиями стало более "streamlined", то есть рациональным и оптимизированным, а также появился акцент на fleet-подход: управление инфраструктурой как "парком платформ".
Fleet Management способен управлять несколькими инстансами VCF, что становится особенно важным для крупных организаций и распределённых инфраструктур. Именно тут виден "архитектурный сдвиг": VCF 9 проектируется не только как платформа для одного частного облака, а как унифицированная экосистема для гибридных и мультиинстанс-сценариев.
Feature transition: замена Workspace ONE Access
Workspace ONE Access удалён -> VCF Identity Broker
Одно из самых "жёстких" изменений — это не ребрендинг, а полная замена компонента. Workspace ONE Access полностью удалён (removed), вместо него введён новый компонент VCF Identity Broker. Это новый компонент для управления идентификацией (identity management), интеграции доступа, IAM-сценариев (identity access management), интеграции авторизации/аутентификации для экосистемы VCF.
Миграция и перемещение рабочих нагрузок: HCX теперь - часть Operations
VMware HCX -> VCF Operations HCX
HCX остаётся инструментом для пакетной миграции виртуальных машин (bulk migration) и миграций из одной локации в другую (в т.ч. удалённые площадки). Но в VCF 9 меняется позиционирование продукта: он теперь полностью интегрирован в VCF Operations и называется VCF Operations HCX. То есть HCX становится частью единого "операционного" контура VCF 9.
Автоматизация: упрощение названий и интеграция компонентов
Aria Automation -> VCF Automation
Это компонент автоматизации, отвечающий за сценарии и рабочие процессы частного облака, развертывание рабочих нагрузок и ежедневные операции. В VCF 9 это просто VCF Automation.
Orchestrator используется для end-to-end рабочих процессов и автоматизации процессов создания ВМ и операций. В VCF 9 это теперь просто VCF Operations Orchestrator. Это важно: Orchestrator закрепляется как часть "operations-логики", а не просто автономный компонент автоматизации.
VMware Cloud Director: интеграция/поглощение в VCF Automation
Теперь VMware Cloud Director имеет новое позиционирование: продукт полностью интегрирован в VCF Automation. То есть Cloud Director как самостоятельное наименование уходит на второй план, а функции “переезжают” или связываются с модулем VCF Automation.
Слой Kubernetes: vSphere with Tanzu -> vSphere Supervisor
vSphere with Tanzu переименован в vSphere Supervisor
Это важное изменение, отражающее стратегию VCF по треку modern apps. Supervisor рассматривается как компонент для приложений новой волны, перехода monolith > microservices, контейнерного слоя и инфраструктуры enterprise-grade Kubernetes.
Платформа VCF при этом описывается как:
Unified Cloud Platform
Подходит для частного облака
Интегрируется с hyperscalers (AWS, Azure, Google Cloud и т.д.)
Поддерживает enterprise Kubernetes services
Итоги: что означает переход VCF 5 -> VCF 9 для архитектуры и миграции
Переход от VCF 5.x к VCF 9 — это комбинация трёх больших тенденций:
1) Унификация бренда и операционной модели
Aria-компоненты массово становятся частью семейства VCF Operations.
2) Улучшение управления жизненным циклом
LCM эволюционирует в Fleet Management, что отражает переход к управлению группами платформ и множественными VCF-инстансами.
3) Feature transitions (замены функций и ролей компонентов)
Самое заметное — удаление Workspace ONE Access и введение VCF Identity Broker.
Cоответствие компонентов VCF 5.x и VCF 9
SDDC Manager -> SDDC Manager (улучшен)
Aria Operations -> VCF Operations
Aria Operations for Logs -> VCF Operations for Logs
Aria Operations for Network Insights -> VCF Operations for Network
Aria LCM -> VCF Operations Fleet Management
Workspace ONE Access -> VCF Identity Broker (замена продукта)
Виртуализация давно стала неотъемлемой частью корпоративной ИТ-инфраструктуры, позволяя эффективнее использовать серверное оборудование и быстро развертывать новые сервисы. До недавнего времени российский рынок практически полностью зависел от зарубежных продуктов – особенно от VMware, на долю которого приходилось до 95% внедрений. Однако после 2022 года ситуация резко изменилась: VMware покинула российский рынок, отключив аккаунты пользователей и прекратив поддержку.
Это оставило компании без обновлений, техподдержки и возможности покупки новых лицензий. Одновременно регуляторы ужесточили требования: с 1 января 2025 года значимые объекты критической информационной инфраструктуры (КИИ) обязаны использовать только отечественное ПО. В результате переход на российские системы виртуализации из опции превратился в необходимость, и за три года рынок претерпел заметную консолидацию.
По данным исследования компании «Код Безопасности», уже 78% российских организаций выбирают отечественные средства виртуализации. В реестре российского ПО на 2025 год значатся порядка 92 решений для серверной виртуализации, из которых реально «живых» около 30, а активно используемых – не более десятка. За короткий срок появились аналоги западных продуктов «большой тройки» (VMware, Microsoft Hyper-V, Citrix) и собственные разработки российских компаний. Рассмотрим новейшие российские платформы виртуализации серверов и инфраструктуры виртуальных рабочих мест (VDI) и проанализируем их архитектуру, производительность, безопасность, возможности VDI, а также функции кластеризации и управления ресурсами. Отдельно сравним их с VMware VCF/vSphere по функциональности, зрелости технологий, совместимости и поддержке – и определим, какие решения наиболее перспективны для импортозамещения VMware в корпоративных ИТ России.
Российские платформы виртуализации 2025 года представлены широким спектром архитектурных подходов. Условно можно выделить две ключевые категории: классическая архитектура и гиперконвергентная архитектура (HCI). Также различаются технологические основы: часть решений опирается на открытый исходный код (форки oVirt, OpenStack, Proxmox и др.), тогда как другие являются проприетарными разработками.
Классическая архитектура
В классической схеме вычислительные узлы, системы хранения (СХД) и сети реализуются отдельными компонентами, объединёнными в единый кластер виртуализации. Такой подход близок к VMware vSphere и проверен десятилетиями: он даёт максимальную гибкость, позволяя подключать внешние высокопроизводительные СХД, использовать существующие сетевые инфраструктуры и масштабировать каждый слой независимо (например, наращивать хранение без изменения серверов). Для организаций с уже развернутыми дорогими СХД и развитой экспертизой администраторов этот вариант наиболее понятен.
Многие отечественные продукты поддерживают классическую модель. Например, “Ред Виртуализация” (решение компании РЕД СОФТ на базе KVM/oVirt), zVirt от Orion soft, SpaceVM (платформа компании «ДАКОМ М»), Rosa Virtualization, VMmanager от ISPsystem и Numa vServer (Xen-based) – все они ориентированы на традиционную архитектуру с интеграцией внешних хранилищ и сетей.
Архитектурно они во многом схожи с VMware (например, оVirt-платформы реализуют подключение SAN-хранилищ, динамическую балансировку ресурсов и т.п. «из коробки»). Однако есть и недостатки классического подхода: более высокая стоимость отдельных компонентов (CAPEX), требовательность к квалификации узких специалистов, сложность диагностики сбоев (не всегда очевидно, в каком слое проблема). Развёртывание классической инфраструктуры может занимать больше времени, поскольку нужно поэтапно настроить и интегрировать разнородные компоненты внутри единой платформы.
Гиперконвергентная инфраструктура (HCI)
В HCI все основные функции – вычисления, хранение, сеть – объединены на каждом узле и управляются через единую программную платформу. Локальные диски серверов объединяются программно в распределённое хранилище (часто на основе Ceph или аналогов), а сеть виртуализуется средствами самой платформы. Такой подход упрощает масштабирование: добавление нового узла сразу увеличивает и CPU/RAM, и объём хранения. Гиперконвергенция особенно хорошо подходит для распределённых площадок и филиалов, где нет штата ИТ-специалистов – достаточно поставить несколько одинаковых узлов, и система автонастроится без тонкой ручной оптимизации каждого слоя.
В России к HCI-решениям относятся, например, vStack (платформа в составе холдинга ITG на базе FreeBSD и гипервизора bhyve), «Кибер Инфраструктура» (решение компании «Киберпротект», развившей технологии Acronis), Р-платформа (российская приватная облачная платформа), Горизонт-ВС и др. – они изначально спроектированы как гиперконвергентные. Некоторые HCI-системы позволяют выходить за рамки встроенного хранения – например, Кибер Инфраструктура и Горизонт-ВС поддерживают подключение внешних блочных СХД, комбинируя подходы.
Открытый код или собственные разработки?
Многие отечественные продукты выросли из популярных open-source проектов. Например, решения на основе oVirt – это упомянутые выше zVirt, Red Виртуализация, ROSA Virtualization, HostVM и др. Их преимущество – быстрое получение базовой функциональности (live migration, подключение SAN, кластеры HA и т.д.) благодаря наследию oVirt/Red Hat. Однако после ухода Red Hat из oVirt сообщество ослабло, и российским командам пришлось форкать код и развивать его самим.
Orion soft, например, пошла по пути создания собственного бэкенда поверх ядра oVirt, сумев сохранить совместимость, но упростив и улучшив часть функций для пользователей. Другой популярный открытый проект – Proxmox VE – тоже получил российские форки (например, «Альт Виртуализация», GloVirt), что позволяет заказчикам использовать знакомый интерфейс PVE с поддержкой отечественной компанией.
Есть и решения на базе OpenStack – эта платформа хорошо масштабируется и подходит для построения частных облаков IaaS. Так, AccentOS CE – российская облачная платформа на основе OpenStack – получила сертификат ФСТЭК осенью 2025 г. Тем не менее, OpenStack-системы (например, частное облако VK Cloud) часто критикуют за избыточную сложность для задач традиционной виртуализации и проблемы стабильности отдельных ВМ под высокими нагрузками хранения. Наконец, существуют продукты на базе Xen – в частности, Numa vServer построен на открытом гипервизоре xcp-ng (форк Citrix XenServer), что даёт вариант для тех, кто привык к Xen.
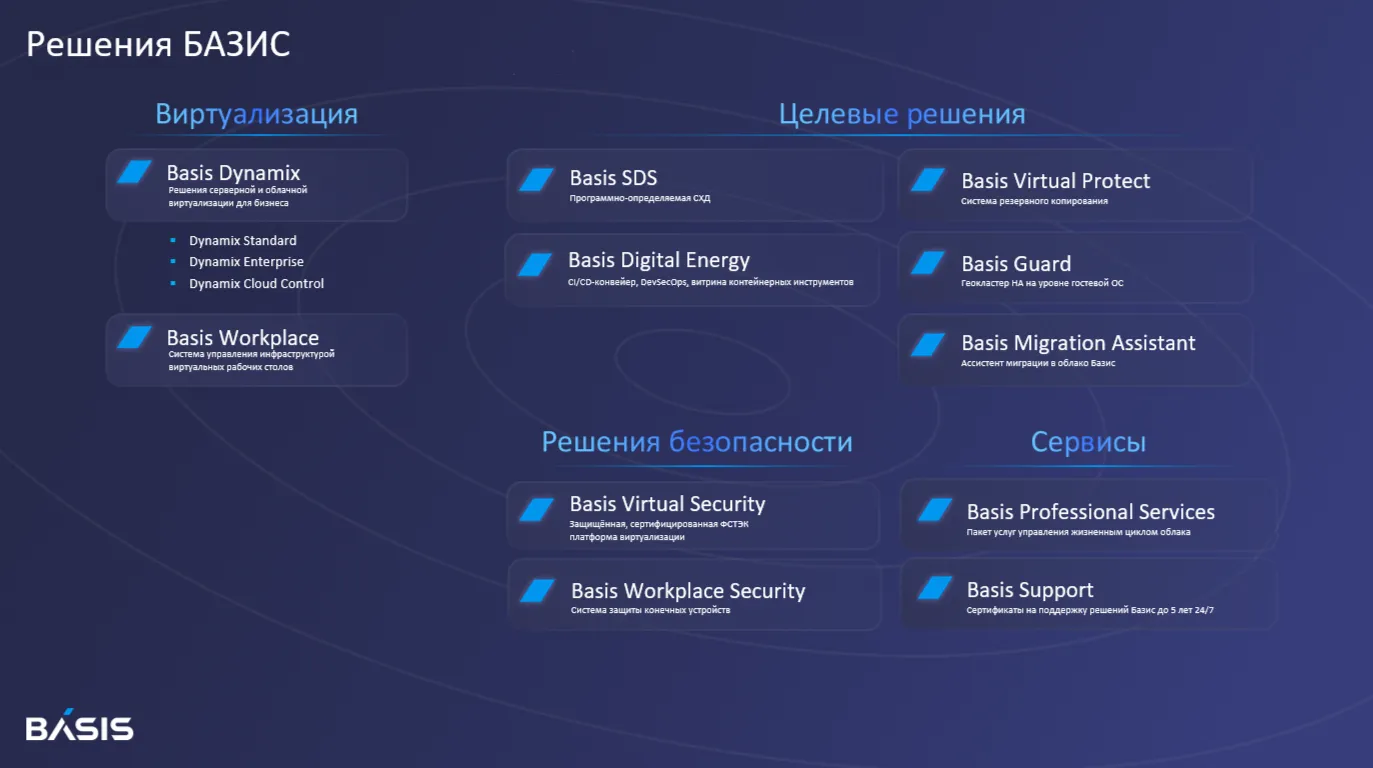
Помимо форков, на рынке появились принципиально новые разработки. К ним относятся SpaceVM, Basis Dynamix, VMmanager и др., где компании создали собственные платформы управления, опираясь на комбинацию различных open-source компонентов, но реализуя уникальные возможности. Например, SpaceVM и Basis Dynamix заявляют о полном проприетарном стеке – разработчики утверждают, что не используют готовые open-source продукты внутри, а все компоненты (гипервизор, драйверы, диспетчер ресурсов) созданы самостоятельно. Такой подход требует больше усилий, но позволяет глубже интегрировать систему с отечественными ОС и средствами кибербезопасности, а также активно внедрять API-first и DevOps-интеграции. В итоге, сегодня российский рынок виртуализации предлагает решения на любой вкус – от максимально близких к VMware аналогов на базе KVM до совершенно новых платформ с оригинальной архитектурой.
Один из ключевых вопросов для корпоративных клиентов – способен ли отечественный гипервизор обеспечить производительность и масштаб, сопоставимые с vSphere. Практика показывает, что большинство российских платформ уже поддерживают необходимые уровни масштабирования: кластеры на десятки узлов, сотни и тысячи виртуальных машин, live migration и распределение нагрузки между хостами. Например, платформа SpaceVM официально поддерживает кластеры до 96 серверов, Selectel Cloud – до 2500 узлов, Red Виртуализация – до 250 хостов в одном датацентре.
Многие разработчики вообще не указывают жестких ограничений на размер кластера, утверждая, что он линеен (ISP VMmanager протестирован на 350+ узлов, 1000+ ВМ). В реальных внедрениях обычно речь идёт о десятках серверов, что этим решениям вполне по силам. Однако из опыта миграций известны и проблемы: так, эксперты отмечают, что у zVirt иногда возникают сложности при росте кластера более 50 узлов. Первые «тревожные звоночки» появлялись уже около 20 хостов, но в новых версиях горизонтальная масштабируемость доведена до 50–60 узлов, что для большинства сред достаточно. Подобные нюансы следует учитывать при проектировании – предельно возможный масштаб у разных продуктов разнится, и при планировании очень крупных инсталляций лучше привлечь вендора или интегратора для оценки нагрузок.
По производительности виртуальных машин отечественные гипервизоры стараются минимизировать накладные расходы. Так, vStack HCP заявляет о оверхеде всего 2–5% к CPU при виртуализации, то есть близкой к нативной производительности. Это достигнуто за счёт легковесного гипервизора (базирующегося на bhyve) и оптимизированного I/O стека. Большинство других решений используют проверенные гипервизоры (KVM, Xen), у которых производительность также высока. С точки зрения нагрузки на оперативную память и хранилище – многое зависит от механизмов дедупликации, компрессии и прочих оптимизаций в конкретной реализации.
Здесь можно отметить, что многие российские платформы уже внедрили современные технологии оптимизации ресурсов: поддержка NUMA для эффективной работы с многопроцессорными узлами, возможность тонкого выделения ресурсов (thin provisioning дисков, memory ballooning) и т.д. Например, по данным рейтинга Компьютерры, Basis Dynamix и SpaceVM набрали максимальные баллы по критериям вертикальной и горизонтальной масштабируемости, а также поддержки Intel VT-x/AMD-V виртуализации, NUMA и даже GPU-passthrough. То есть функционально они не уступают VMware в возможностях задействовать современное оборудование.
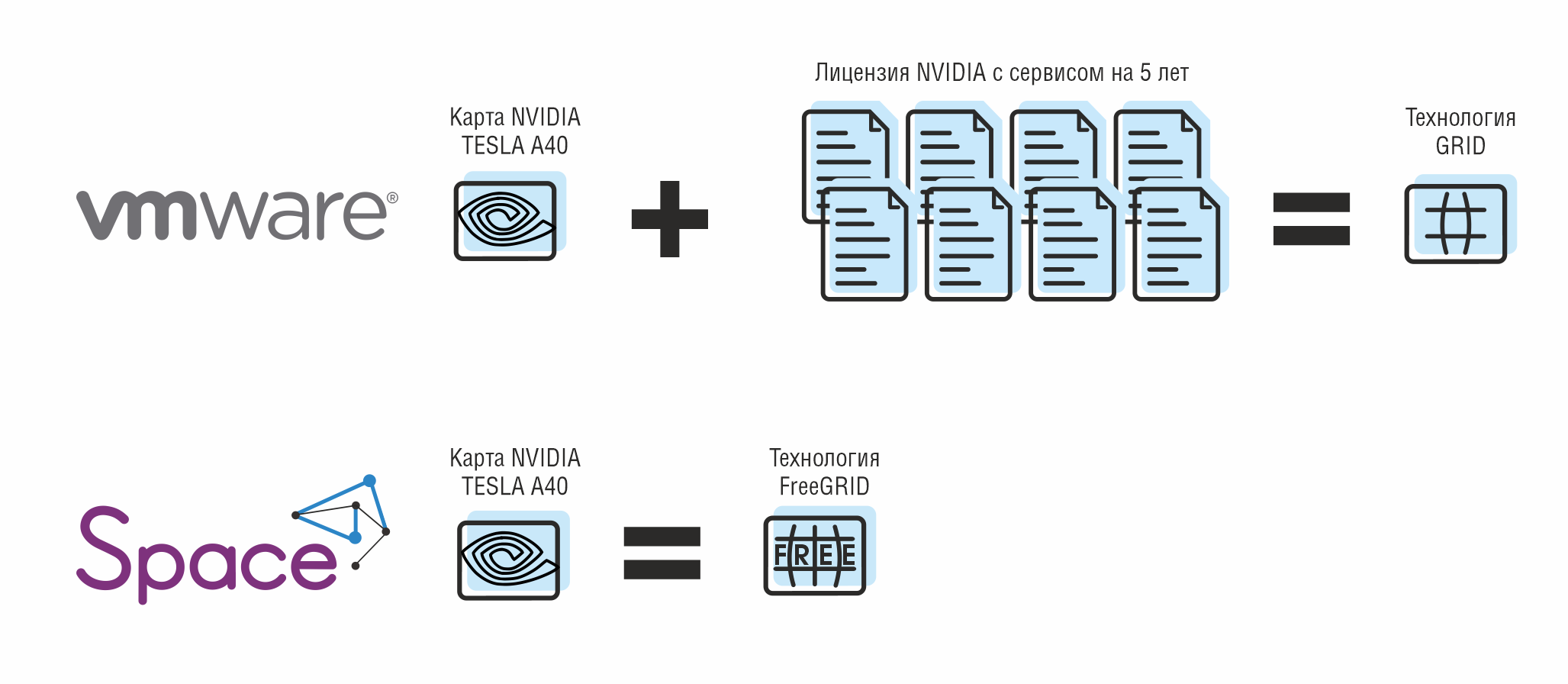
Отдельно стоит упомянуть работу с графическими нагрузками. В сфере VDI и 3D-приложений критична поддержка GPU-виртуализации. Здесь российские разработчики сделали заметный прогресс. SpaceVM изначально ориентирован на сценарии с графическими рабочими станциями: платформа поддерживает как passthrough GPU для выделения целой видеокарты ВМ, так и технологию FreeGRID – собственную разработку для виртуализации ресурсов NVIDIA-GPU без риска лицензионной блокировки.
По сути, FreeGRID выступает аналогом технологии NVIDIA vGPU (GRID), но адаптированным к ограничениям поставок – это актуально, поскольку официальные лицензии NVIDIA в России недоступны. Благодаря этому SpaceVM активно используют организации, которым нужны высокопроизводительные графические ВМ: конструкторские бюро (CAD/CAE), геоинформационные системы, видеомонтаж и др. Другие платформы также не отстают: zVirt и решения на базе oVirt умеют пробрасывать физические GPU внутрь ВМ, а HostVM и ряд VDI-платформ заявляют поддержку технологии виртуализации графических процессоров для нужд 3D-моделирования. Таким образом, в плане работы с тяжелыми графическими нагрузками отечественные продукты закрывают основные потребности.
Стоит отметить, что автоматическое распределение ресурсов и балансовка нагрузки – функции, известные в VMware как DRS (Distributed Resource Scheduler) – начинают появляться и в российских решениях. Например, zVirt реализует модуль автоматического распределения виртуальных машин по хостам, аналогичный DRS. Это значит, что платформа сама перераспределяет ВМ при изменении нагрузок, поддерживая равномерное потребление ресурсов. Кроме того, большинство продуктов поддерживают «горячую миграцию» (Live Migration) – перенос работающей ВМ между хостами без простоя, а также миграцию хранилищ на лету (Storage vMotion) – например, в zVirt есть возможность "перетаскивать" виртуальные диски между датацентрами без остановки ВМ. Эти функции критичны для обеспечения непрерывности сервисов при обслуживании оборудования или ребалансировке нагрузки.
Резюмируя, производительность российских гипервизоров уже находится на уровне, достаточном для многих корпоративных задач, а по некоторым параметрам они предлагают интересные инновации (минимальный оверхэд у vStack, поддержка GPU через FreeGRID у SpaceVM и т.п.). Тем не менее, при планировании очень нагруженных или масштабных систем следует внимательно относиться к тестированию конкретного продукта под своей нагрузкой – практика показывает, что в пилотных проектах не всегда выявляются узкие места, которые могут проявиться на продакшен-системе. Важны также оперативность вендора при оптимизации производительности и наличие у него экспертизы для помощи заказчику в тюнинге – эти аспекты мы рассмотрим в следующих статьях при сравнении опций поддержки.
Вопрос кибербезопасности и соответствия регуляторным требованиям (ФСТЭК, Закон о КИИ, ГОСТ) является определяющим для многих российских предприятий, особенно государственных и критической инфраструктуры. Отечественные решения виртуализации учитывают эти аспекты с самого начала разработки. Во-первых, практически все крупные платформы включены в Единый реестр российского ПО, что подтверждает их юридическую «отечественность» и позволяет использовать их для импортозамещения в госорганизациях. Более того, ряд продуктов прошёл добровольную сертификацию в ФСТЭК России по профильным требованиям безопасности.
Особое внимание уделяется сетевой безопасности в виртуальной среде. Одной из угроз в датацентрах является горизонтальное распространение атак между ВМ по внутренней сети. Для борьбы с этим современные платформы внедряют микросегментацию сети и распределённые виртуальные брандмауэры. Например, zVirt содержит встроенные средства SDN (Software-Defined Networking) для сегментации трафика – администратор может разделить виртуальную сеть на множество изолированных сегментов и централизованно задать политики доступа между ними. Эта функциональность, требуемая ФСТЭК для защиты виртуальных сред, реализована по умолчанию и позволяет соответствовать требованиям закона по сегментированию значимых объектов КИИ и ГосИС.
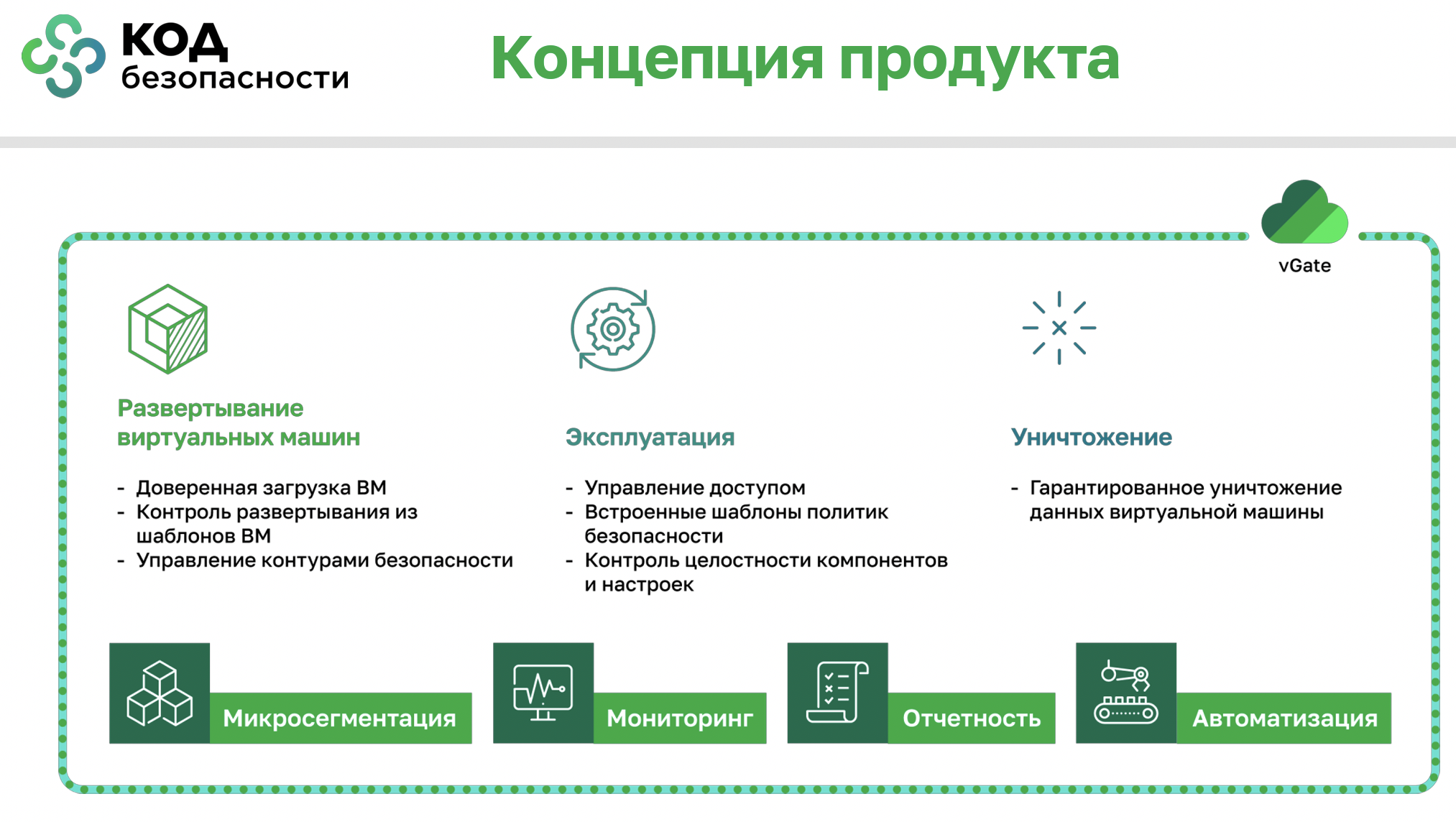
Дополнительно компания Orion soft (разработчик zVirt) рекомендует использовать совместно с гипервизором продукт vGate от компании «Код Безопасности». vGate – это межсетевой экран уровня гипервизора, который интегрируется с платформой виртуализации. Работая на уровне гипервизора, vGate перехватывает и фильтрует трафик между всеми ВМ, применяя централизованные политики безопасности. Разработчики сделали ставку на микросегментацию: каждый узел vGate хранит полный набор правил, что позволяет при миграции ВМ сразу переносить и её сетевые политики.
vGate сертифицирован ФСТЭК как межсетевой экран класса «Б» с 4-м уровнем доверия, поэтому его связка с zVirt закрывает требования регулятора для защиты виртуальных сегментов КИИ. В случае комбинированного использования, как отмечают эксперты, правила безопасности контролируются одновременно на уровне платформы (zVirt SDN) и на уровне гипервизора (vGate), дополняя друг друга. Например, если политика zVirt разрешает определённый трафик между ВМ, а политика vGate запрещает, пакет будет блокирован – то есть действует наиболее строгий из двух наборов правил. Такой «двойной заслон» повышает уверенность в защите.
Кроме сетевых экранов, встроенные механизмы безопасности практически обязательны для всех современных платформ. Российские решения включают разграничение доступа и аутентификацию корпоративного уровня: реализованы ролевые модели (RBAC), интеграция с LDAP/Active Directory для централизованного управления учетными записями, поддержка многофакторной аутентификации администраторов и журналирование действий с возможностью отправки логов на SIEM-системы. По этим пунктам разница с VMware не такая и большая – например, Basis Dynamix, SpaceVM и Red Виртуализация имеют полный набор RBAC/LDAP/2FA и получили максимально возможные оценки за безопасность в независимом рейтинге.
Дополнительно некоторые решения обеспечивают контроль целостности и доверенную загрузку (Trusted Boot) за счёт интеграции с отечественными защищёнными ОС. Например, гипервизоры могут устанавливаться поверх сертифицированных ОС (РЕД ОС, Astra Linux), что обеспечивает соответствие по требованиям НДВ (недекларированных возможностей) и использование российских криптосредств.
В контексте соответствия требованиям регуляторов важна и сертификация самих платформ виртуализации. На конец 2025 года сертифицированных по профильным требованиям ФСТЭК именно гипервизоров немного (преимущественно решения для гостевых ОС специального назначения). Однако, как отмечалось, платформы часто используют сертифицированные СЗИ «поверх» (антивирусы, СОВ, vGate и др.) для обеспечения соответствия. Кроме того, крупнейшие заказчики – госсектор, банки – проводили оценочные испытания продуктов в своих пилотных зонах. Например, при миграции в Альфа-Банке и АЛРОСА основным драйвером был закон о КИИ, и в обоих случаях итоговый выбор пал на отечественные гипервизоры (SpaceVM и zVirt соответственно) после тщательного тестирования безопасности. Таким образом, можно сказать, что российские системы виртуализации в целом готовы к работе в защищённых контурах. Они позволяют реализовать требуемую сегментацию, поддерживают российские криптоалгоритмы (при использовании соответствующих ОС и библиотек), а при правильной настройке обеспечивают изоляцию ВМ не хуже зарубежных аналогов.
Нельзя не затронуть и вопрос устойчивости к атакам и сбоям. Эксперты отмечают, что по методам защиты виртуальная инфраструктура не сильно отличается от физической – нужны регулярные обновления безопасности, сильные пароли и ограничение доступа привилегированных пользователей. Основной вектор атаки на гипервизоры в России – компрометация учётных данных администраторов, тогда как эксплойты уязвимостей встречаются гораздо реже. Это значит, что внедрение RBAC/2FA, о которых сказано выше, существенно снижает риски. Также важно строить резервное копирование на уровне приложений и данных, а не полагаться только на механизмы платформы. Как отмечают представители банковского сектора, добиться требуемого по стандартам времени восстановления (RTO) только силами гипервизора сложно – необходимо комбинировать различные уровни (репликация критичных систем, отказоустойчивые кластеры, резервные площадки). В целом же, за три года уровень зрелости безопасности российских продуктов заметно вырос: многие проблемы, ранее считавшиеся нерешаемыми, уже устранены или существуют понятные обходные пути. Производители активно учитывают требования заказчиков, внедряя наиболее востребованные функции безопасности в приоритетном порядке.
VMware Cloud Foundation (VCF) 9.0 предоставляет быстрый и простой способ развертывания частного облака. Хотя обновление с VCF 5.x спроектировано как максимально упрощённое, оно вносит обязательные изменения в методы управления и требует аккуратного, поэтапного выполнения.
Недавно Джонатан Макдональд провёл насыщенный вебинар вместе с Брентом Дугласом, где они подробно разобрали процесс обновления с VCF 5.2 до VCF 9.0. Сотни участников и шквал вопросов ясно показали, что этот переход сейчас волнует многих клиентов VMware.
Джонатан отфильтровал повторяющиеся вопросы, объединив похожие в единые, комплексные темы. Ниже представлены 10 ключевых вопросов («must-know»), заданных аудиторией, вместе с подробными ответами, которые помогут вам уверенно пройти путь к VCF 9.0.
Вопрос 1: Как VMware SDDC Manager выполняет обновления? Есть ли значительные изменения в обновлениях версии 9.0?
Было много вопросов, связанных с SDDC Manager и процессом обновлений. Существенных изменений в том, как выполняются обновления, нет. Если вы знакомы с VCF 5.2, то асинхронный механизм патчинга встроен в консоль точно так же и в версии 9.0. Это позволяет планировать обновления и патчи по необходимости. Главное отличие заключается в том, что интерфейс SDDC Manager был интегрирован в консоль VCF Operations и теперь находится в разделе управления парком (Fleet Management). Многие рабочие процессы также были перенесены, что позволило консолидировать интерфейсы.
Вопрос 2: Есть ли особенности обновления кластеров VMware vSAN Original Storage Architecture (OSA)?
vSAN OSA не «уходит» и не объявлен устаревшим в VCF 9.0. Аппаратные требования для vSAN Express Storage Architecture (ESA) существенно отличаются и могут быть несовместимы с существующим оборудованием. vSAN OSA — отличный способ продолжать эффективно использовать имеющееся оборудование без необходимости покупать новое. Для самого обновления важно проверить совместимость аппаратного обеспечения и прошивок с версией 9.0. Если они поддерживаются, обновление пройдёт так же, как и в предыдущих релизах.
Вопрос 3: Как выполняется обновление VMware NSX?
При обновлении VCF все компоненты, включая NSX, обновляются последовательно. Обычно процесс начинается с компонентов VCF Operations. После этого управление передаётся рабочим процессам SDDC Manager: сначала обновляется сам SDDC Manager, затем NSX, потом VMware vCenter и в конце — хосты VMware ESX.
Вопрос 4: Если VMware Aria Suite развернут в режиме VCF-aware в версии 5.2, нужно ли отвязывать Aria Suite перед обновлением?
Нет. Вы можете сначала обновить компоненты Aria Suite до версии, совместимой с VCF 9, а затем продолжить обновление остальных компонентов.
Вопрос 5: Можно ли обновиться с VCF 5.2 без настроенных LCM и Aria Suite?
Да. Наличие компонентов Aria Suite до обновления на VCF 9.0 не требуется. Однако в рамках обновления будут развернуты Aria Lifecycle (в версии 9.0 — VCF Fleet Management) и VCF Operations, так как они являются обязательными компонентами в 9.0.
Вопрос 6: Сколько хостов допускается в консолидированном дизайне VCF 9.0?
Для нового консолидированного дизайна рекомендуется минимум четыре хоста. При конвергенции инфраструктуры с использованием vSAN требуется минимум три ESX-хоста (четыре рекомендуются для отказоустойчивости). При использовании внешних систем хранения достаточно минимум двух хостов. Что касается максимальных значений, документированных ограничений нет, кроме ограничений VMware vSphere: 96 хостов на кластер и 2500 хостов на один vCenter. В целом рекомендуется по мере роста добавлять дополнительные домены рабочих нагрузок или кластеры для логического разделения среды с точки зрения производительности, доступности и восстановления.
Вопрос 7: Как перейти с VMware Identity Manager (vIDM) на VCF Identity Broker (VIDB) в VCF 9?
Прямого пути обновления или миграции с vIDM на VIDB не существует. Требуется «чистое» (greenfield) развертывание VIDB. Это особенно актуально, если используется VCF Automation, так как в этом случае новое развертывание VIDB является обязательным.
Вопрос 8: Нужно ли загружать дистрибутивы для VCF Operations и куда их помещать?
Это зависит от используемого сценария. В общем случае, если вы выполняете обновление и компоненты Aria ещё не установлены, потребуется загрузить и развернуть виртуальные машины VCF Operations и VCF Operations Fleet Management. После их развертывания бинарные файлы загружаются в репозиторий (depot) VCF Operations Fleet Management для установки дополнительных компонентов. Если вы конвергируете vSphere в VCF, все недостающие компоненты будут развернуты установщиком VCF, и, соответственно, должны быть загружены в него заранее.
Вопрос 9: Существует ли путь отката (rollback), если во время обновления возникла ошибка?
В целом не существует «кнопки отката» для всего VCF сразу. Лучше рассматривать каждое последовательное обновление как контрольную точку. Например, перед обновлением SDDC Manager с 5.2 до 9.0 нужно всегда делать резервную копию. Если во время обновления возникает сбой, можно откатиться к состоянию до ошибки и продолжить диагностику. То же самое относится к другим компонентам. При сбоях в обновлении NSX, vCenter или ESX-хостов нужно оценить ситуацию и либо выполнить откат, либо обратиться в поддержку, если время окна обслуживания истекает и необходимо срочно восстановить работоспособность среды. Именно поэтому тщательное планирование имеет решающее значение при любом обновлении VCF.
Вопрос 10: Существует ли путь миграции с VMware Cloud Director (VCD) на VCF Automation?
На данный момент VCD не поддерживается в VCF 9.0, и официальных путей миграции не существует. Если у вас есть вопросы по этому поводу, обратитесь к вашему Account Director.
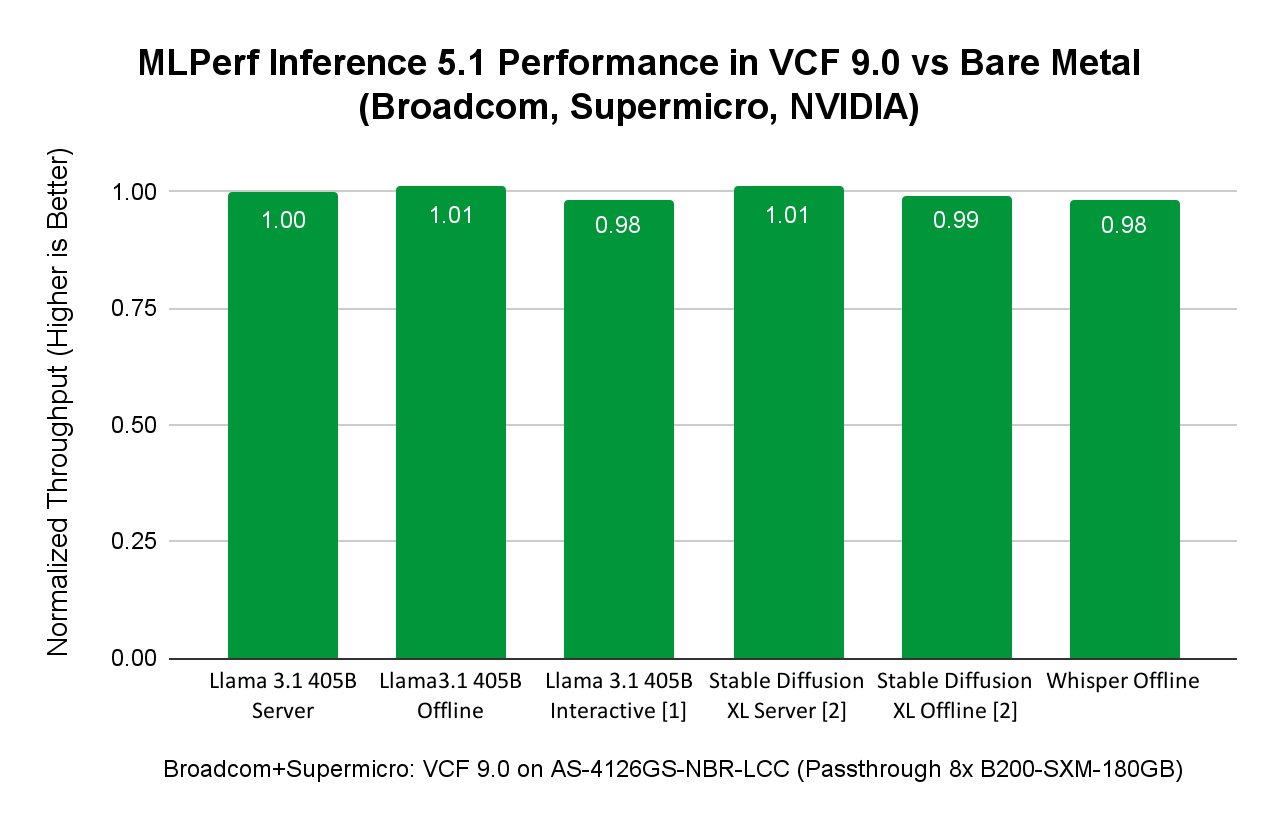
Broadcom в сотрудничестве с Dell, Intel, NVIDIA и SuperMicro недавно продемонстрировала преимущества виртуализации, представив результаты MLPerf Inference v5.1. Платформа VMware Cloud Foundation (VCF) 9.0 показала производительность, сопоставимую с bare metal, по ключевым AI-бенчмаркам, включая Speech-to-Text (Whisper), Text-to-Video (Stable Diffusion XL), большие языковые модели (Llama 3.1-405B и Llama 2-70B), графовые нейронные сети (R-GAT) и компьютерное зрение (RetinaNet). Эти результаты были достигнуты как на GPU-, так и на CPU-решениях с использованием виртуализированных конфигураций NVIDIA с 8x H200 GPU, GPU 8x B200 в режиме passthrough/DirectPath I/O, а также виртуализированных двухсокетных процессоров Intel Xeon 6787P.
Для прямого сравнения соответствующих метрик смотрите официальные результаты MLCommons Inference 5.1. Этими результатами Broadcom вновь демонстрирует, что виртуализованные среды VCF обеспечивают производительность на уровне bare metal, позволяя заказчикам получать преимущества в виде повышенной гибкости, доступности и адаптивности, которые предоставляет VCF, при сохранении отличной производительности.
VMware Private AI — это архитектурный подход, который балансирует бизнес-выгоды от AI с требованиями организации к конфиденциальности и соответствию нормативам. Основанный на ведущей в отрасли платформе частного облака VMware Cloud Foundation (VCF), этот подход обеспечивает конфиденциальность и контроль данных, выбор между решениями с открытым исходным кодом и коммерческими AI-платформами, а также оптимальные затраты, производительность и соответствие требованиям.
Private AI позволяет предприятиям использовать широкий спектр AI-решений в своей среде — NVIDIA, AMD, Intel, проекты сообщества с открытым исходным кодом и независимых поставщиков программного обеспечения. С VMware Private AI компании могут развертывать решения с уверенностью, зная, что Broadcom выстроила партнерства с ведущими поставщиками AI-технологий. Broadcom добавляет мощь своих партнеров — Dell, Intel, NVIDIA и SuperMicro — в VCF, упрощая управление дата-центрами с AI-ускорением и обеспечивая эффективную разработку и выполнение приложений для ресурсоемких AI/ML-нагрузок.
В тестировании были показаны три конфигурации в VCF:
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC с NVLink-соединенными 8x B200 в режиме DirectPath I/O
Dell PowerEdge XE9680 с NVLink-соединенными 8x H200 в режиме vGPU
Конфигурация 1-node-2S-GNR_86C_ESXi_172VCPU-VM с процессорами Intel® Xeon® 6787P с 86 ядрами.
Производительность MLPerf Inference 5.1 с VCF на сервере SuperMicro с NVIDIA 8x B200
VCF поддерживает как DirectPath I/O, так и технологии NVIDIA Virtual GPU (vGPU) для использования GPU в задачах AI и других GPU-ориентированных нагрузках. Для демонстрации AI-производительности с GPU NVIDIA B200 был выбран DirectPath I/O для бенчмаркинга MLPerf Inference.
Инженеры запускали нагрузки MLPerf Inference на сервере SuperMicro SuperServer AS-4126GS-NBR-LCC с восемью GPU NVIDIA SXM B200 с 180 ГБ HBM3e при использовании VCF 9.0.0.
В таблице ниже показаны аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на bare metal и виртуализированных системах. Бенчмарки были оптимизированы с помощью NVIDIA TensorRT-LLM. TensorRT-LLM включает в себя компилятор глубокого обучения TensorRT и содержит оптимизированные ядра, этапы пред- и пост-обработки, а также примитивы меж-GPU и межузлового взаимодействия, обеспечивая выдающуюся производительность на GPU NVIDIA.
Параметр
Bare Metal
Виртуальная среда
Система
SuperMicro GPU SuperServer SYS-422GA-NBRT-LCC
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC
Процессоры
2x Intel Xeon 6960P, 72 ядра
2x AMD EPYC 9965, 192 ядра
Логические процессоры
144
192 из 384 (50%) выделены виртуальной машине для инференса (при загрузке CPU менее 10%). Таким образом, 192 остаются доступными для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
GPU
8x NVIDIA B200, 180 ГБ HBM3e
DirectPath I/O, 8x NVIDIA B200, 180 ГБ HBM3e
Межсоединение ускорителей
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
Память
2,3 ТБ
Память хоста — 3 ТБ, 2,5 ТБ выделено виртуальной машине для инференса
Хранилище
4x NVMe SSD по 15,36 ТБ
4x NVMe SSD по 13,97 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.9 и драйвер 575.57.08
CUDA 12.8 и драйвер 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
Сравнение производительности виртуализованных и bare metal ML/AI-нагрузок на примере сервера SuperMicro SuperServer AS-4126GS-NBR-LCC:
Некоторые моменты:
Результат сценария Llama 3.1 405B в интерактивном режиме не был верифицирован Ассоциацией MLCommons. Broadcom и SuperMicro не отправляли его на проверку, поскольку это не требовалось.
Результаты Stable Diffusion XL, представленные Broadcom и SuperMicro, не могли быть напрямую сопоставлены с результатами SuperMicro на том же оборудовании, поскольку SuperMicro не отправляла результаты бенчмарка Stable Diffusion на платформе bare metal. Поэтому сравнение выполнено с другой заявкой, использующей сопоставимый хост с 8x NVIDIA B200-SXM-180GB.
Рисунок выше показывает, что AI/ML-нагрузки инференса из различных доменов — LLM (Llama 3.1 с 405 млрд параметров), Speech-to-Text (Whisper от OpenAI) и Text-to-Image (Stable Diffusion XL) — в VCF достигают производительности, сопоставимой с bare metal. При запуске AI/ML-нагрузок в VCF пользователи получают преимущества управления датацентром, предоставляемые VCF, при сохранении производительности на уровне bare metal.
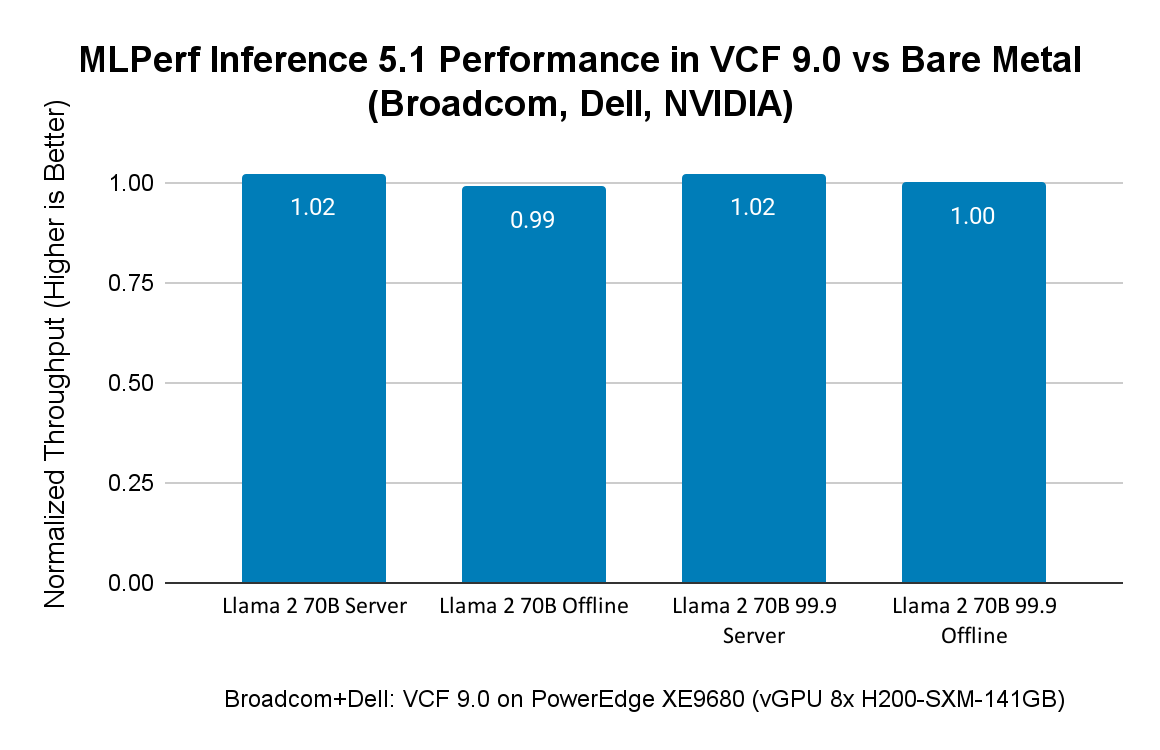
Производительность MLPerf Inference 5.1 с VCF на сервере Dell с NVIDIA 8x H200
Broadcom поддерживает корпоративных заказчиков, использующих AI-инфраструктуру от различных аппаратных вендоров. В рамках раунда заявок для MLPerf Inference 5.1, VMware совместно с NVIDIA и Dell продемонстрировала VCF 9.0 как отличную платформу для AI-нагрузок, особенно для генеративного AI. Для бенчмаркинга был выбран режим vGPU, чтобы показать еще один вариант развертывания, доступный заказчикам в VCF 9.0.
Функциональность vGPU, интегрированная с VCF, предоставляет ряд преимуществ для развертывания и управления AI-инфраструктурой. Во-первых, VCF формирует группы устройств из 2, 4 или 8 GPU с использованием NVLink и NVSwitch. Эти группы могут выделяться различным виртуальным машинам, обеспечивая гибкость распределения GPU-ресурсов в соответствии с требованиями нагрузок и повышая утилизацию GPU.
Во-вторых, vGPU позволяет нескольким виртуальным машинам совместно использовать GPU-ресурсы на одном хосте. Каждой ВМ выделяется часть памяти GPU и/или вычислительных ресурсов GPU в соответствии с профилем vGPU. Это дает возможность нескольким небольшим нагрузкам совместно использовать один GPU, исходя из их требований к памяти и вычислениям, что повышает плотность консолидации, максимизирует использование ресурсов и снижает затраты на развертывание AI-инфраструктуры.
В-третьих, vGPU обеспечивает гибкое управление дата-центрами с GPU, поддерживая приостановку/возобновление работы виртуальных машин и VMware vMotion (примечание: vMotion поддерживается только в том случае, если AI-нагрузки не используют функцию Unified Virtual Memory GPU).
И наконец, vGPU позволяет различным GPU-ориентированным нагрузкам (таким как AI, графика или другие высокопроизводительные вычисления) совместно использовать одни и те же физические GPU, при этом каждая нагрузка может быть развернута в отдельной гостевой операционной системе и принадлежать разным арендаторам в мультиарендной среде.
VMware запускала нагрузки MLPerf Inference 5.1 на сервере Dell PowerEdge XE9680 с восемью GPU NVIDIA SXM H200 с 141 ГБ HBM3e при использовании VCF 9.0.0. Виртуальным машинам в тестах была выделена лишь часть ресурсов bare metal. В таблице ниже представлены аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на системах bare metal и в виртуализированной среде.
Аппаратное и программное обеспечение для Dell PowerEdge XE9680:
Параметр
Bare Metal
Виртуальная среда
Система
Dell PowerEdge XE9680
Dell PowerEdge XE9680
Процессоры
Intel Xeon Platinum 8568Y+, 96 ядер
Intel Xeon Platinum 8568Y+, 96 ядер
Логические процессоры
192
Всего 192, 48 (25%) выделены виртуальной машине для инференса, 144 доступны для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
Память хоста — 3 ТБ, 2 ТБ (67%) выделено виртуальной машине для инференса
Хранилище
2 ТБ SSD, 5 ТБ CIFS
2x SSD по 3,5 ТБ, 1x SSD на 7 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.8 и драйвер 570.133
CUDA 12.8 и драйвер Linux 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
Результаты MLPerf Inference 5.1, представленные в таблице, демонстрируют высокую производительность для больших языковых моделей (Llama 3.1 405B и Llama 2 70B), а также для задач генерации изображений (SDXL — Stable Diffusion).
Результаты MLPerf Inference 5.1 при использовании 8x vGPU в VCF 9.0 на аппаратной платформе Dell PowerEdge XE9680 с 8x GPU NVIDIA H200:
Бенчмарки
Пропускная способность
Llama 3.1 405B Server (токенов/с)
277
Llama 3.1 405B Offline (токенов/с)
547
Llama 2 70B Server (токенов/с)
33 385
Llama 2 70B Offline (токенов/с)
34 301
Llama 2 70B — высокая точность — Server (токенов/с)
33 371
Llama 2 70B — высокая точность — Offline (токенов/с)
34 486
SDXL Server (сэмплов/с)
17,95
SDXL Offline (сэмплов/с)
18,64
На рисунке ниже сравниваются результаты MLPerf Inference 5.1 в VCF с результатами Dell на bare metal на том же сервере Dell PowerEdge XE9680 с GPU H200. Результаты как Broadcom, так и Dell находятся в открытом доступе на сайте MLCommons. Поскольку Dell представила только результаты для Llama 2 70B, на рисунке 2 показано сравнение производительности MLPerf Inference 5.1 в VCF 9.0 и на bare metal именно для этих нагрузок. Диаграмма демонстрирует, что разница в производительности между VCF и bare metal составляет всего 1–2%.
Сравнение производительности виртуализированных и bare metal ML/AI-нагрузок на Dell XE9680 с 8x GPU H200 SXM 141 ГБ:
Производительность MLPerf Inference 5.1 в VCF с процессорами Intel Xeon 6-го поколения
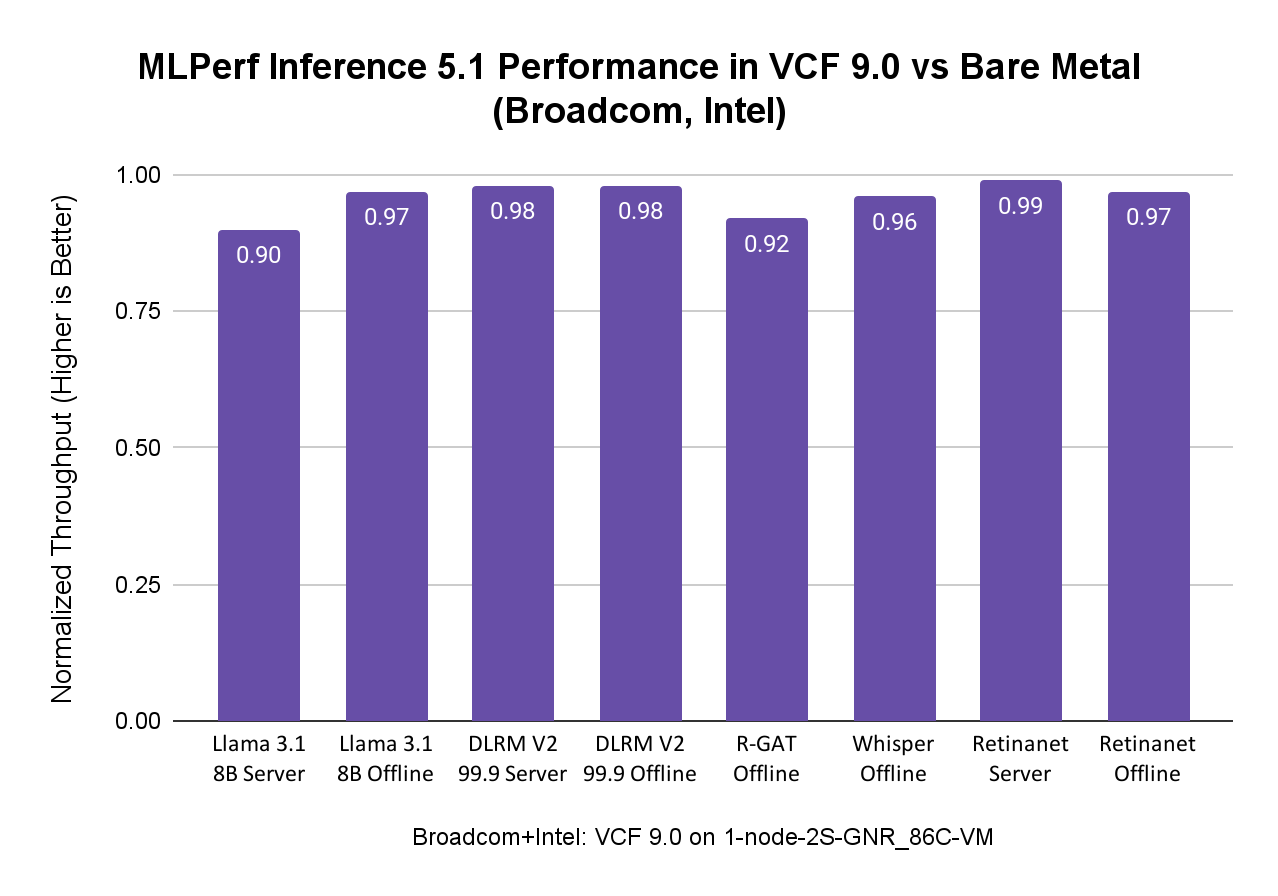
Intel и Broadcom совместно продемонстрировали возможности VCF, ориентированные на заказчиков, использующих исключительно процессоры Intel Xeon со встроенным ускорением AMX для AI-нагрузок. В тестах запускали нагрузки MLPerf Inference 5.1, включая Llama 3.1 8B, DLRM-V2, R-GAT, Whisper и RetinaNet, на системе, представленной в таблице ниже.
Аппаратное и программное обеспечение для систем Intel
AI-нагрузки, особенно модели меньшего размера, могут эффективно выполняться на процессорах Intel Xeon с ускорением AMX в среде VCF, достигая производительности, близкой к bare metal, и одновременно получая преимущества управляемости и гибкости VCF. Это делает процессоры Intel Xeon отличной отправной точкой для организаций, начинающих свой путь в области AI, поскольку они могут использовать уже имеющуюся инфраструктуру.
Результаты MLPerf Inference 5.1 при использовании процессоров Intel Xeon в VCF показывают производительность на уровне bare metal. В сценариях, где в датацентре отсутствуют ускорители, такие как GPU, или когда AI-нагрузки менее вычислительно требовательны, в зависимости от задач заказчика, AI/ML-нагрузки могут быть развернуты на процессорах Intel Xeon в VCF с преимуществами виртуализации и при сохранении производительности на уровне bare metal, как показано на рисунке ниже:
Бенчмарки MLPerf Inference
Каждый бенчмарк определяется набором данных (Dataset) и целевым уровнем качества (Quality Target). В следующей таблице приведено краткое описание бенчмарков, входящих в данную версию набора тестов (официальные правила остаются первоисточником):
В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему (SUT) в самом начале прогона. В сценарии Server LoadGen отправляет новые запросы в SUT в соответствии с распределением Пуассона. Это показано в таблице ниже.
Сценарии тестирования MLPerf Inference:
Сценарий
Генерация запросов
Длительность
Сэмплов на запрос
Ограничение по задержке
Tail latency
Метрика производительности
Server
LoadGen отправляет новые запросы в SUT согласно распределению Пуассона
270 336 запросов и 60 секунд
1
Зависит от бенчмарка
99%
Максимально поддерживаемый параметр пропускной способности Пуассона
VCF предоставляет заказчикам несколько гибких вариантов развертывания AI-инфраструктуры, поддерживает оборудование от различных вендоров и позволяет использовать разные подходы к запуску AI-нагрузок, применяющих как GPU, так и CPU для вычислений.
При использовании GPU виртуализированные конфигурации виртуальных машин в наших бенчмарках задействуют лишь часть ресурсов CPU и памяти, при этом обеспечивая производительность MLPerf Inference 5.1 на уровне bare metal даже при пиковом использовании GPU — это одно из ключевых преимуществ виртуализации. Такой подход позволяет задействовать оставшиеся ресурсы CPU и памяти для выполнения других нагрузок с полной изоляцией, снизить стоимость AI/ML-инфраструктуры и использовать преимущества виртуализации VCF при управлении датацентрами.
Результаты бенчмарков показывают, что VCF 9.0 находится в «зоне Златовласки» для AI/ML-нагрузок, обеспечивая производительность, сопоставимую с bare metal. VCF также упрощает управление и быструю обработку нагрузок благодаря использованию vGPU, гибких NVLink-соединений между устройствами и технологий виртуализации, позволяющих применять AI/ML-инфраструктуру для графики, обучения и инференса. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой, обеспечивая совместное использование дорогостоящих аппаратных ресурсов несколькими арендаторами.
VMware vCenter Converter – это классический инструмент VMware для перевода физических и виртуальных систем в формат виртуальных машин VMware. Его корни уходят к утилите VMware P2V Assistant, которая существовала в 2000-х годах для «Physical-to-Virtual» миграций. В 2007 году VMware выпустила первую версию Converter (3.0), заменив P2V Assistant...
NVIDIA Run:ai ускоряет операции AI с помощью динамической оркестрации ресурсов, максимизируя использование GPU, обеспечивая комплексную поддержку жизненного цикла AI и стратегическое управление ресурсами. Объединяя ресурсы между средами и применяя продвинутую оркестрацию, NVIDIA Run:ai значительно повышает эффективность GPU и пропускную способность рабочих нагрузок.
Недавно VMware объявила, что предприятия теперь могут развертывать NVIDIA Run:ai с встроенной службой VMware vSphere Kubernetes Services (VKS) — стандартной функцией в VMware Cloud Foundation (VCF). Это поможет предприятиям достичь оптимального использования GPU с NVIDIA Run:ai, упростить развертывание Kubernetes и поддерживать как контейнеризованные нагрузки, так и виртуальные машины на VCF. Таким образом, можно запускать AI- и традиционные рабочие нагрузки на единой платформе.
Давайте посмотрим, как клиенты Broadcom теперь могут развертывать NVIDIA Run:ai на VCF, используя VMware Private AI Foundation with NVIDIA, чтобы развертывать кластеры Kubernetes для AI, максимизировать использование GPU, упростить операции и разблокировать GenAI на своих приватных данных.
NVIDIA Run:ai на VCF
Хотя многие организации по умолчанию запускают Kubernetes на выделенных серверах, такой DIY-подход часто приводит к созданию изолированных инфраструктурных островков. Это заставляет ИТ-команды вручную создавать и управлять службами, которые VCF предоставляет из коробки, лишая их глубокой интеграции, автоматизированного управления жизненным циклом и устойчивых абстракций для вычислений, хранения и сетей, необходимых для промышленного AI. Именно здесь платформа VMware Cloud Foundation обеспечивает решающее преимущество.
vSphere Kubernetes Service — лучший способ развертывания Run:ai на VCF
Наиболее эффективный и интегрированный способ развертывания NVIDIA Run:ai на VCF — использование VKS, предоставляющего готовые к корпоративному использованию кластеры Kubernetes, сертифицированные Cloud Native Computing Foundation (CNCF), полностью управляемые и автоматизированные. Затем NVIDIA Run:ai развертывается на этих кластерах VKS, создавая единую, безопасную и устойчивую платформу от аппаратного уровня до уровня приложений AI.
Ценность заключается не только в запуске Kubernetes, но и в запуске его на платформе, решающей базовые корпоративные задачи:
Снижение совокупной стоимости владения (TCO) с помощью VCF: уменьшение инфраструктурных изолятов, использование существующих инструментов и навыков без переобучения, единое управление жизненным циклом всех инфраструктурных компонентов.
Единые операции: основаны на привычных инструментах, навыках и рабочих процессах с автоматическим развертыванием кластеров и GPU-операторов, обновлениями и управлением в большом масштабе.
Запуск и управление Kubernetes для большой инфраструктуры: встроенный, сертифицированный CNCF Kubernetes runtime с полностью автоматизированным управлением жизненным циклом.
Поддержка в течение 24 месяцев для каждой минорной версии vSphere Kubernetes (VKr) - это снижает нагрузку при обновлениях, стабилизирует окружения и освобождает команды для фокусировки на ценности, а не на постоянных апгрейдах.
Лучшая конфиденциальность, безопасность и соответствие требованиям: безопасный запуск чувствительных и регулируемых AI/ML-нагрузок со встроенными средствами управления, приватности и гибкой безопасностью на уровне кластеров.
Сетевые возможности контейнеров с VCF
Сети Kubernetes на «железе» часто плоские, сложные для настройки и требующие ручного управления. В крупных централизованных кластерах обеспечение надежного соединения между приложениями с разными требованиями — сложная задача. VCF решает это с помощью Antrea, корпоративного интерфейса контейнерной сети (CNI), основанного на CNCF-проекте Antrea. Он используется по умолчанию при активации VKS и обеспечивает внутреннюю сетевую связность, реализацию политик сети Kubernetes, централизованное управление политиками и операции трассировки (traceflow) с уровня управления NSX. При необходимости можно выбрать Calico как альтернативу.
Расширенная безопасность с vDefend
Разные приложения в общем кластере требуют различных политик безопасности и контроля доступа, которые сложно реализовать последовательно и масштабируемо. Дополнение VMware vDefend для VCF расширяет возможности безопасности, позволяя применять сетевые политики Antrea и микросегментацию уровня «восток–запад» вплоть до контейнера. Это позволяет ИТ-отделам программно изолировать рабочие нагрузки AI, конвейеры данных и пространства имен арендаторов с помощью политик нулевого доверия. Эти функции необходимы для соответствия требованиям и предотвращения горизонтального перемещения в случае взлома — уровень детализации, крайне сложный для реализации на физических коммутаторах.
Высокая отказоустойчивость и автоматизация с VMware vSphere
Это не просто удобство, а основа устойчивости инфраструктуры. Сбой физического сервера, выполняющего многодневное обучение, может привести к значительным потерям времени. VCF, основанный на vSphere HA, автоматически перезапускает такие рабочие нагрузки на другом узле.
Благодаря vMotion возможно обслуживание оборудования без остановки AI-нагрузок, а Dynamic Resource Scheduler (DRS) динамически балансирует ресурсы, предотвращая перегрузки. Подобная автоматическая устойчивость отсутствует в статичных, выделенных средах.
Гибкое управление хранилищем с политиками через vSAN
AI-нагрузки требуют разнообразных типов хранения — от высокопроизводительного временного пространства для обучения до надежного объектного хранения для наборов данных. vSAN позволяет задавать эти требования (например, производительность, отказоустойчивость) индивидуально для каждой рабочей нагрузки. Это предотвращает появление новых изолированных инфраструктур и необходимость управлять несколькими хранилищами, как это часто бывает в средах на «голом железе».
Преимущества NVIDIA Run:ai
Максимизация использования GPU: динамическое выделение, дробление GPU и приоритизация задач между командами обеспечивают максимально эффективное использование мощной инфраструктуры.
Масштабируемые сервисы AI: поддержка развертывания больших языковых моделей (инференс) и других сложных AI-задач (распределённое обучение, тонкая настройка) с эффективным масштабированием ресурсов под изменяющуюся нагрузку.
Обзор архитектуры
Давайте посмотрим на высокоуровневую архитектуру решения:
VCF: базовая инфраструктура с vSphere, сетями VCF (включая VMware NSX и VMware Antrea), VMware vSAN и системой управления VCF Operations.
Кластер Kubernetes с поддержкой AI: управляемый VCF кластер VKS, обеспечивающий среду выполнения AI-нагрузок с доступом к GPU.
Панель управления NVIDIA Run:ai: доступна как услуга (SaaS) или для локального развертывания внутри кластера Kubernetes для управления рабочими нагрузками AI, планирования заданий и мониторинга.
Кластер NVIDIA Run:ai: развернут внутри Kubernetes для оркестрации GPU и выполнения рабочих нагрузок.
Рабочие нагрузки data science: контейнеризированные приложения и модели, использующие GPU-ресурсы.
Эта архитектура представляет собой полностью интегрированный программно-определяемый стек. Вместо того чтобы тратить месяцы на интеграцию разрозненных серверов, коммутаторов и систем хранения, VCF предлагает единый, эластичный и автоматизированный облачный операционный подход, готовый к использованию.
Диаграмма архитектуры
Существует два варианта установки панели управления NVIDIA Run:ai:
SaaS: панель управления размещена в облаке (см. https://run-ai-docs.nvidia.com/saas). Локальный кластер Run:ai устанавливает исходящее соединение с облачной панелью для выполнения рабочих нагрузок AI. Этот вариант требует исходящего сетевого соединения между кластером и облачным контроллером Run:ai.
Самостоятельное размещение: панель управления Run:ai устанавливается локально (см. https://run-ai-docs.nvidia.com/self-hosted) на кластере VKS, который может быть совместно используемым или выделенным только для Run:ai. Также доступен вариант с изолированной установкой (без подключения к сети).
Вот визуальное представление инфраструктурного стека:
Сценарии развертывания
Сценарий 1: Установка NVIDIA Run:ai на экземпляре VCF с включенной службой vSphere Kubernetes Service
Предварительные требования:
Среда VCF с узлами ESX, оснащёнными GPU
Кластер VKS для AI, развернутый через VCF Automation
GPU настроены как DirectPath I/O, vGPU с разделением по времени (time-sliced) или NVIDIA Multi-Instance GPU (MIG)
Если используется vGPU, NVIDIA GPU Operator автоматически устанавливается в рамках шаблона (blueprint) развертывания VCFA.
Основные шаги по настройке панели управления NVIDIA Run:ai:
Подготовьте ваш кластер VKS, назначенный для роли панели управления NVIDIA Run:ai, выполнив все необходимые предварительные условия.
Создайте секрет с токеном, полученным от NVIDIA Run:ai, для доступа к контейнерному реестру NVIDIA Run:ai.
Если используется VMware Data Services Manager, настройте базу данных Postgres для панели управления Run:ai; если нет — Run:ai будет использовать встроенную базу Postgres.
Добавьте репозиторий Helm и установите панель управления с помощью Helm.
Основные шаги по настройке кластера:
Подготовьте кластер VKS, назначенный для роли кластера, с выполнением всех предварительных условий, и запустите диагностический инструмент NVIDIA Run:ai cluster preinstall.
Установите дополнительные компоненты, такие как NVIDIA Network Operator, Knative и другие фреймворки в зависимости от ваших сценариев использования.
Войдите в веб-консоль NVIDIA Run:ai, перейдите в раздел Resources и нажмите "+New Cluster".
Следуйте инструкциям по установке и выполните команды, предоставленные для вашего кластера Kubernetes.
Преимущества:
Полный контроль над инфраструктурой
Бесшовная интеграция с экосистемой VCF
Повышенная надежность благодаря автоматизации vSphere HA, обеспечивающей защиту длительных AI-тренировок и серверов инференса от сбоев аппаратного уровня — критического риска для сред на «голом железе».
Сценарий 2: Интеграция vSphere Kubernetes Service с существующими развертываниями NVIDIA Run:ai
Почему именно vSphere Kubernetes Service:
Управляемый VMware Kubernetes упрощает операции с кластерами
Тесная интеграция со стеком VCF, включая VCF Networking и VCF Storage
Возможность выделить отдельный кластер VKS для конкретного приложения или этапа — разработка, тестирование, продакшн
Шаги:
Подключите кластер(ы) VKS к существующей панели управления NVIDIA Run:ai, установив кластер Run:ai и необходимые компоненты.
Настройте квоты GPU и политики рабочих нагрузок в пользовательском интерфейсе NVIDIA Run:ai.
Используйте возможности Run:ai, такие как автомасштабирование и разделение GPU, с полной интеграцией со стеком VCF.
Преимущества:
Простота эксплуатации
Расширенная наблюдаемость и контроль
Упрощённое управление жизненным циклом
Операционные инсайты: преимущество "Day 2" с VCF
Наблюдаемость (Observability)
В средах на «железе» наблюдаемость часто достигается с помощью разрозненного набора инструментов (Prometheus, Grafana, node exporters и др.), которые оставляют «слепые зоны» в аппаратном и сетевом уровнях. VCF, интегрированный с VCF Operations (часть VCF Fleet Management), предоставляет единую панель мониторинга для наблюдения и корреляции производительности — от физического уровня до гипервизора vSphere и кластера Kubernetes.
Теперь в системе появились специализированные панели GPU для VCF Operations, предоставляющие критически важные данные о том, как GPU и vGPU используются приложениями. Этот глубокий AI-ориентированный анализ позволяет гораздо быстрее выявлять и устранять узкие места.
Резервное копирование и восстановление (Backup & Disaster Recovery)
Velero, интегрированный с vSphere Kubernetes Service через vSphere Supervisor, служит надежным инструментом резервного копирования и восстановления для кластеров VKS и pod’ов vSphere. Он использует Velero Plugin for vSphere для создания моментальных снапшотов томов и резервного копирования метаданных напрямую из хранилища Supervisor vSphere.
Это мощная стратегия резервирования, которая может быть интегрирована в планы аварийного восстановления всей AI-платформы (включая состояние панели управления Run:ai и данные), а не только бездисковых рабочих узлов.
Итог: Bare Metal против VCF для корпоративного AI
Аспект
Kubernetes на «голом железе» (подход DIY)
Платформа VMware Cloud Foundation (VCF)
Сеть (Networking)
Плоская архитектура, высокая сложность, ручная настройка сетей.
Программно-определяемая сеть с использованием VCF Networking.
Безопасность (Security)
Трудно обеспечить защиту; политики безопасности применяются вручную.
Точная микросегментация до уровня контейнера при использовании vDefend; программные политики нулевого доверия (Zero Trust).
Высокие риски: сбой сервера может вызвать значительные простои для критических задач, таких как обучение и инференс моделей.
Автоматическая отказоустойчивость с помощью vSphere HA (перезапуск нагрузок), vMotion (обслуживание без простоя) и DRS (балансировка нагрузки).
Хранилище (Storage)
Приводит к «изолированным островам» и множеству разнородных систем хранения.
Единое, управляемое политиками хранилище через VCF Storage; предотвращает изоляцию и упрощает управление.
Резервное копирование и восстановление (Backup & DR)
Часто реализуется в последнюю очередь; чрезвычайно сложный и трудоемкий процесс.
Встроенные снимки CSI и автоматизированное резервное копирование на уровне Supervisor с помощью Velero.
Наблюдаемость (Observability)
Набор разрозненных инструментов с «слепыми зонами» в аппаратной и сетевой частях.
Единая панель наблюдения (VCF Operations) с коррелированным сквозным мониторингом — от оборудования до приложений.
Управление жизненным циклом (Lifecycle Management)
Ручное, трудоёмкое управление жизненным циклом всех компонентов.
Автоматизированное, полноуровневое управление жизненным циклом через VCF Operations.
Общая модель (Overall Model)
Заставляет ИТ-команды вручную собирать и интегрировать множество разнородных инструментов.
Единая, эластичная и автоматизированная облачная операционная модель с встроенными корпоративными сервисами.
NVIDIA Run:ai на VCF ускоряет корпоративный ИИ
Развертывание NVIDIA Run:ai на платформе VCF позволяет предприятиям создавать масштабируемые, безопасные и эффективные AI-платформы. Независимо от того, начинается ли внедрение с нуля или совершенствуются уже существующие развертывания с использованием VKS, клиенты получают гибкость, высокую производительность и корпоративные функции, на которые они могут полагаться.
VCF позволяет компаниям сосредоточиться на ускорении разработки AI и повышении отдачи от инвестиций (ROI), а не на рискованной и трудоемкой задаче построения и управления инфраструктурой. Она предоставляет автоматизированную, устойчивую и безопасную основу, необходимую для промышленных AI-нагрузок, позволяя NVIDIA Run:ai выполнять свою главную задачу — максимизировать использование GPU.
С выходом VMware Cloud Foundation 9.0 произошёл переломный момент в подходе к связыванию vCenter. VCF 9 вводит принципиально новую архитектуру единого входа (Single Sign-On) для всех компонентов частного облака, устраняя необходимость в классическом ELM для объединения серверов vCenter. Фактически, в окружениях на базе VCF 9 Enhanced Linked Mode более не используется для объединения vCenter в единый домен SSO...
Команда поддержки VMware в Broadcom полностью привержена тому, чтобы помочь клиентам в процессе обновлений. Поскольку дата окончания общего срока поддержки VMware vSphere 7 наступила 2 октября 2025 года, многие пользователи обращаются к вендору в поисках лучших практик и пошаговых руководств по обновлению. И на этот раз речь идет не только об обновлениях с VMware vSphere 7 до VMware vSphere 8. Наблюдается активный рост подготовки клиентов к миграции с vSphere 7 на VMware Cloud Foundation (VCF) 9.0.
Планирование и выполнение обновлений может вызывать стресс, поэтому в VMware решили, что новый набор инструментов для обновления будет полезен клиентам. Чтобы сделать процесс максимально гладким, техническая команда VMware подготовила полезные ресурсы для подготовки к апгрейдам, которые помогут обеспечить миграцию инфраструктуры без серьезных проблем.
Чтобы помочь в этом процессе, каким бы он ни был, были подготовлены руководства в формате статей базы знаний (KB), которые проведут вас через весь процесс от начала до конца. Этот широкий набор статей базы знаний по обновлениям продуктов предоставляет простые, пошаговые инструкции по процессу обновления, выделяя области, требующие особого внимания, на каждом из следующих этапов:
Подготовка к обновлению
Последовательность и порядок выполнения апгрейда
Необходимые действия после переезда и миграции
Ниже приведен набор статей базы знаний об обновлениях, с которым настоятельно рекомендуется ознакомиться до проведения обновления инфраструктуры vSphere и других компонентов платформы VCF.
Одной из новых возможностей Fleet Management, представленных в VMware Cloud Foundation (VCF) 9.0, является полностью обновлённый опыт единого входа (SSO), обеспечивающий доступ администраторов ко всем основным интерфейсам управления, таким как: VCF Operations, vSphere Client, NSX Manager и другие. Новый компонент VCF Identity Broker (VIDB) поддерживает множество современных провайдеров идентификации, а также традиционные службы каталогов. В этой статье вы узнаете, как включить и настроить SSO в среде VCF 9.
Режимы развертывания – встроенный или внешний (appliance)
Первым шагом при включении VCF SSO является выбор режима развертывания брокера идентификации. Существует два варианта: встроенный или appliance.
Встроенный вариант интегрирован с vCenter Server в домене управления и идеально подходит для небольших сред VCF, которым не требуется масштабирование до целого пула экземпляров VCF.
Для большей масштабируемости можно выбрать вариант appliance, который работает на небольшом кластере из трёх узлов VIDB для обеспечения отказоустойчивости. Внешний вариант может предоставлять службы идентификации для всего пула экземпляров VCF и рекомендуется для инфраструктур до пяти экземпляров VCF.
Поддержка провайдеров идентификации
После выбора режима развертывания необходимо выбрать провайдера идентификации. В VCF 9 добавлена поддержка Ping Identity и универсальных провайдеров SAML 2.0 в дополнение к Okta, Entra ID, Active Directory, OpenLDAP и другим. В зависимости от выбранного провайдера будут доступны различные варианты определения групп, которым предоставляется доступ для входа в компоненты VCF. Для уточнения конкретных требований следует обратиться к документации продукта.
Ещё одним улучшением стали методы предоставления пользователей и групп: теперь, помимо SCIM с современными провайдерами идентификации, можно использовать JIT или AD/LDAP.
Конфигурация компонентов
После настройки провайдера идентификации остаётся всего один шаг, чтобы включить VCF SSO для каждого компонента в развертывании. Настройка основных инфраструктурных компонентов — vCenter Server и NSX Manager — сводится к простому выбору опции, при этом несколько сервисов можно активировать одновременно, и процесс занимает всего несколько минут.
Для компонентов управления процесс почти такой же простой, но каждый из них расположен в отдельном узле в дереве навигации, поэтому достаточно перейти туда и следовать инструкциям в интерфейсе, чтобы завершить настройку SSO.
Назначение ролей
После завершения настройки VCF SSO остаётся административная задача — назначить необходимые роли для каждого компонента. Эта одноразовая операция должна выполняться с использованием локальных учётных записей администратора (например, “admin” или “administrator@vsphere.local” в случае с vCenter Server). Необходимо предоставить доступ пользователям и группам, созданным через настроенного провайдера идентификации, и назначить им соответствующие права для управления компонентами.
Процесс может отличаться в зависимости от компонента. Например, вы можете назначить группе роль Enterprise Admin, чтобы она могла управлять NSX.
Чтобы увидеть весь процесс включения доступа в полном развертывании VCF 9, посмотрите демо ниже.
Пользовательский интерфейс SDDC Manager
Особое примечание о SDDC Manager в VCF 9: этот пользовательский интерфейс считается устаревшим, но остаётся доступным, а само backend-приложение по-прежнему необходимо для выполнения некоторых задач управления инфраструктурой. В связи с этим войти в интерфейс SDDC Manager с использованием учётных данных VCF SSO невозможно — продолжайте использовать локальную учётную запись администратора, обычно administrator@vsphere.local.
Однако у SDDC Manager всё же есть конфигурация SSO, и её следует настроить для удалённого доступа к API. Это связано с тем, что после входа в vCenter Server некоторые действия, инициированные в vSphere Client, фактически выполняются SDDC Manager в фоновом режиме, и для этого потребуется аутентификация. Поэтому назначьте группе SSO, которую вы используете в vCenter Server, права администратора в SDDC Manager, чтобы обеспечить плавный и бесшовный доступ.
Практическая демонстрация
Если вы хотите увидеть полный процесс настройки VCF SSO, ознакомьтесь с этим короткой практической лабораторной работой (HOL), которая пошагово проводит через весь процесс: https://labs.hol.vmware.com/HOL/catalog/lab/26724.
Итоги
Новый релиз VMware Cloud Foundation привносит значительные изменения в рабочие процессы администраторов, особенно за счёт объединения множества административных и управленческих задач в новый интерфейс VCF Operations. Однако по-прежнему существуют специализированные консоли управления, к которым администраторам необходимо получать доступ. Теперь, благодаря VCF SSO и VIDB, переход к выполнению определённых действий в NSX Manager или vSphere Client стал значительно проще. Настройка VCF SSO лёгкая, а безопасность при этом не страдает благодаря интеграции с проверенными и надёжными провайдерами идентификации.
На выступлении в рамках конференции Explore 2025 Крис Вулф объявил о поддержке DirectPath для GPU в VMware Private AI, что стало важным шагом в упрощении управления и масштабировании корпоративной AI-инфраструктуры. DirectPath предоставляет виртуальным машинам эксклюзивный высокопроизводительный доступ к GPU NVIDIA, позволяя организациям в полной мере использовать возможности графических ускорителей без дополнительной лицензионной сложности. Это упрощает эксперименты, прототипирование и перевод AI-проектов в производственную среду. Кроме того, VMware Private AI размещает модели ближе к корпоративным данным, обеспечивая безопасные, эффективные и экономичные развертывания. Совместно разработанное Broadcom и NVIDIA решение помогает компаниям ускорять инновации при снижении совокупной стоимости владения (TCO).
Эти достижения появляются в критически важный момент. Обслуживание передовых LLM-моделей (Large Language Models) — таких как DeepSeek-R1, Meta Llama-3.1-405B-Instruct и Qwen3-235B-A22B-thinking — на полной длине контекста зачастую превышает возможности одного сервера с 8 GPU и картой H100, что делает распределённый инференс необходимым. Агрегирование ресурсов нескольких GPU-узлов позволяет эффективно запускать такие модели, но при этом создаёт новые вызовы в управлении инфраструктурой, оптимизации межсерверных соединений и планировании рабочих нагрузок.
Именно здесь ключевую роль играет решение VMware Cloud Foundation (VCF). Это первая в отрасли платформа частного облака, которая сочетает масштаб и гибкость публичного облака с безопасностью, отказоустойчивостью и производительностью on-premises — и всё это с меньшей стоимостью владения. Используя такие технологии, как NVIDIA NVLink, NVSwitch и GPUDirect RDMA, VCF обеспечивает высокую пропускную способность и низкую задержку коммуникаций между узлами. Также гарантируется эффективное использование сетевых соединений, таких как InfiniBand (IB) и RoCEv2 (RDMA over Converged Ethernet), снижая издержки на коммуникацию, которые могут ограничивать производительность распределённого инференса. С VCF предприятия могут развернуть продуктивный распределённый инференс, добиваясь стабильной работы даже самых крупных reasoning-моделей с предсказуемыми характеристиками.
Использование серверов HGX для максимальной производительности
Серверы NVIDIA HGX играют центральную роль. Их внутренняя топология — PCIe-коммутаторы, GPU NVIDIA H100/H200 и адаптеры ConnectX-7 IB HCA — подробно описана. Критически важным условием для оптимальной производительности GPUDirect RDMA является соотношение GPU-к-NIC 1:1, что обеспечивает каждому ускорителю выделенный высокоскоростной канал.
Внутриузловая и межузловая коммуникация
NVLink и NVSwitch обеспечивают сверхбыструю связь внутри одного HGX-узла (до 8 GPU), тогда как InfiniBand или RoCEv2 дают необходимую пропускную способность и низкую задержку для масштабирования инференса на несколько серверов HGX.
GPUDirect RDMA в VCF
Включение GPUDirect RDMA в VCF требует особых настроек, таких как активация Access Control Services (ACS) в ESX и Address Translation Services (ATS) на сетевых адаптерах ConnectX-7. ATS позволяет выполнять прямые транзакции DMA между PCIe-устройствами, обходя Root Complex и возвращая производительность, близкую к bare metal, в виртуализированных средах.
Определение требований к серверам
В документ включена практическая методика для расчёта минимального количества серверов HGX, необходимых для инференса LLM. Учитываются такие факторы, как num_attention_heads и длина контекста, а также приведена справочная таблица с требованиями к аппаратному обеспечению для популярных моделей LLM (например, Llama-3.1-405B, DeepSeek-R1, Llama-4-Series, Kimi-K2 и др.). Так, для DeepSeek-R1 и Llama-3.1-405B при полной длине контекста требуется как минимум два сервера H00-HGX.
Обзор архитектуры
Архитектура решения разделена на кластер VKS, кластер Supervisor и критически важные Service VM, на которых работает NVIDIA Fabric Manager. Подчёркивается использование Dynamic DirectPath I/O, которое обеспечивает прямой доступ GPU и сетевых адаптеров (NIC) к рабочим узлам кластера VKS, в то время как NVSwitch передаётся в режиме passthrough к Service VM.
Рабочий процесс развертывания и лучшие практики
В документе рассмотрен 8-шаговый рабочий процесс развертывания, включающий:
Подготовку аппаратного обеспечения и прошивок (включая обновления BIOS и firmware)
Конфигурацию ESX для включения GPUDirect RDMA
Развертывание Service VM
Настройку кластера VKS
Установку операторов (NVIDIA Network и GPU Operators)
Процедуры загрузки хранилища и моделей
Развертывание LLM с использованием SGLang и Leader-Worker Sets (LWS)
Проверку после развертывания
Практические примеры и конфигурации
Приведены конкретные примеры, такие как:
YAML-манифесты для развертывания кластера VKS с узлами-воркерами, поддерживающими GPU.
Конфигурация LeaderWorkerSet для запуска моделей DeepSeek-R1-0528, Llama-3.1-405B-Instruct и Qwen3-235B-A22B-thinking на двух узлах HGX
Индивидуально настроенные файлы топологии NCCL для максимизации производительности в виртуализированных средах
Проверка производительности
Приведены шаги для проверки работы RDMA, GPUDirect RDMA и NCCL в многосерверных конфигурациях. Также включены результаты тестов производительности для моделей DeepSeek-R1-0528 и Llama-3.1-405B-Instruct на 2 узлах HGX с использованием стресс-тестового инструмента GenAI-Perf.
AI и генеративный AI (Gen AI) требуют значительной инфраструктуры, а задачи, такие как тонкая настройка, кастомизация, развертывание и выполнение запросов, могут сильно нагружать ресурсы. Масштабирование этих операций становится проблематичным без достаточной инфраструктуры. Кроме того, необходимо соответствовать различным требованиям в области комплаенса и законодательства в разных отраслях и странах. Решения на базе Gen AI должны обеспечивать контроль доступа, правильное размещение рабочих нагрузок и готовность к аудиту для соблюдения этих стандартов. Чтобы решить эти задачи, Broadcom представила VMware Private AI, которая помогает клиентам запускать модели рядом с их собственными данными. Объединяя инновации обеих компаний, Broadcom и NVIDIA стремятся раскрыть потенциал AI и повысить производительность при более низкой совокупной стоимости владения (TCO).
Технический документ «Развертывание VMware Private AI на серверах HGX с использованием Broadcom Ethernet Networking» подробно описывает сквозное развертывание и конфигурацию, с акцентом на DirectPath I/O (passthrough) для GPU, а также сетевые адаптеры Thor 2 с Ethernet-коммутатором Tomahawk 5. Это руководство необходимо архитекторам инфраструктуры, администраторам VCF и специалистам по data science, которые стремятся достичь оптимальной производительности своих AI-моделей в среде VCF.
Что охватывает этот документ?
Документ предоставляет детальные рекомендации по следующим направлениям:
Адаптеры Broadcom Thor 2 и GPU NVIDIA: как эффективно интегрировать сетевые карты Broadcom и GPU NVIDIA в виртуальные машины глубокого обучения (DLVM) на базе Ubuntu в среде VMware Cloud Foundation (VCF).
Сетевая конфигурация: пошаговые инструкции по настройке Ethernet-адаптеров Thor 2 и коммутаторов Tomahawk 5 для включения RoCE (RDMA over Converged Ethernet) с GPU NVIDIA, что обеспечивает низкую задержку и высокую пропускную способность, критически важные для AI-нагрузок.
Тестирование производительности: процедуры запуска тестов с использованием ключевых библиотек коллективных коммуникаций, таких как NCCL, для проверки эффективности многопроцессорных GPU-операций.
Инференс LLM: рекомендации по запуску и тестированию инференса больших языковых моделей (LLM) с помощью NVIDIA Inference Microservices (NIM) и vLLM, демонстрирующие реальный прирост производительности.
Ключевые особенности решения
Решение, описанное в документе, ориентировано на сертифицированные системы VMware Private AI на базе HGX, которые обычно оснащены 4 или 8 GPU H100/H200 с интерконнектом NVSwitch и NVLink. Целевая среда — это приватное облако на базе VCF, использующее сетевые адаптеры Broadcom 400G BCM957608 NICs и кластеризированные GPU NVIDIA H100, соединённые через Ethernet.
Ключевой аспект данного развертывания — использование DirectPath I/O для GPU и адаптеров Thor2, что обеспечивает выделенный доступ к аппаратным ресурсам и максимальную производительность. В руководстве также подробно рассматриваются следующие важные элементы:
BIOS и прошивки: рекомендуемые конфигурации для серверов HGX, позволяющие раскрыть максимальную производительность.
Настройки ESX: оптимизация ESX для passthrough GPU и сетевых устройств, включая корректную разметку оборудования и конфигурацию ACS (Access Control Services).
Настройки виртуальных машин: кастомизация Deep Learning VM (DLVM) для DirectPath I/O, включая назначение статических IP и важные расширенные параметры ВМ для ускоренного запуска и повышения производительности.
Валидация производительности
Подробные инструкции по запуску RDMA, GPUDirect RDMA с Perftest и тестов NCCL на нескольких узлах с разъяснением ожидаемой пропускной способности и задержек.
Бенчмаркинг виртуальной и bare-metal производительности Llama-3.1-70b NIM с помощью genai-perf, позволяющий достичь результатов, близких к bare-metal.
Использование evalscope для оценки точности и стресс-тестирования производительности передовой модели рассуждений gpt-oss-120b.
Вот интересный результат из исследования, доказывающий, что работа GPU в виртуальной среде ничем не хуже, чем в физической:
Это комплексное руководство является ценным ресурсом для всех, кто стремится развернуть и оптимизировать AI-инференс на надежной виртуальной инфраструктуре с использованием серверов NVIDIA HGX и сетевых решений Broadcom Ethernet. Следуя описанным в документе лучшим практикам, организации могут создавать масштабируемые и высокопроизводительные AI-платформы, соответствующие требованиям современных приложений глубокого обучения.
На конференции VMware Explore 2025 компания Broadcom объявила, что службы VMware Private AI Services теперь входят в стандартную поставку VMware Cloud Foundation 9.0 (VCF 9.0). То есть VCF превращается в полноценную AI-native платформу частного облака: из коробки доступны (или будут доступны) сервисы для работы с моделями, наблюдаемость за GPU, среда исполнения для моделей и агент-фреймворк, плюс дорожная карта с MCP, multi-accelerator и AI-ассистентом для VCF.
Платформа VCF 9.0 уже находится в статусе General Availability и доступна с июня 2025, а выход служб Private AI Services в составе подписки планируется к началу первого квартала 2026 финансового года Broadcom.
Давайте посмотрим на состав и функции VMware Private AI Services:
Слой AI-сервисов в VCF 9.0
Что «входит по умолчанию» в Private AI Services (становится частью подписки VCF 9.0):
GPU Monitoring — телеметрия и наблюдаемость графических карт.
Model Store — репозиторий и версионирование моделей.
Model Runtime — сервисный слой для развертывания/экспонирования моделей (endpoints).
Vector Database & Data Indexing/Retrieval — индексация корпоративных данных и RAG-потоки.
Эти возможности поставляются как native services платформы, а не «надстройка» — и это важная архитектурная деталь: AI становится частью инфраструктуры, живущей в тех же сущностных/безопасностных доменах, что и виртуальные машины и контейнеры.
Также были анонсированы следуюие продукты и технологии в рамках дорожной карты:
Intelligent Assist for VCF — LLM-ассистент для диагностики и самопомощи в VCF (пока как tech preview для on-prem/air-gapped и cloud-моделей).
Model Context Protocol (MCP) — стандартная, управляемая интеграция ассистентов с инструментами и БД (Oracle, MSSQL, ServiceNow, GitHub, Slack, PostgreSQL и др.).
Multi-accelerator Model Runtime — единая среда исполнения для AMD и NVIDIA GPU без переработки приложений; поддержка NVIDIA Blackwell, B200, ConnectX-7/BlueField-3 с технологией Enhanced DirectPath I/O.
Multi-tenant Models-as-a-Service — безопасное шаринг-использование моделей между пространствами имен/линиями бизнеса.
Ядро VCF 9.0: что поменялось в самой платформе
Единая операционная плоскость
VCF 9.0 переносит фокус на «One interface to operate» (VCF Operations) и «One interface to consume» (VCF Automation): единая модель политик, API и общий движок жизненного цикла. Это снижает расхождение инструментов и обучаемость. На практике это дает унифицированное управление инфраструктурой, health/patch/compliance из одной консоли, централизованные функции IAM/SSO/сертификатов, анализ корреляции логов и другие возможности.
Примеры экранов и функций, доступных в VCF Operations: обзор по всем инстансам, геокарта, статус сертификатов с автообновлением, NetOps-дэшборды (NSX health, VPC, flows), интеграция Live Recovery и LogAssist.
Слой потребления (для разработчиков/проектных команд)
GitOps (Argo CD) как встроенная модель доставки, Istio Service Mesh для zero-trust/observability трафика, единый контроль политик по проектам.
vSphere Kubernetes Service (VKS) — функции enterprise-K8s, доступные прямо из VCF.
Native vSAN S3 Object Store — S3-совместимый API хранилища объектов на vSAN, без внешних лицензий/модулей.
Все это — официальные «новые в 9.0» элементы, влияющие на скорость доставки сервисов и безопасность.
Производительность и эффективность
NVMe Memory Tiering — расширение оперативной памяти за счет NVMe для высокочастотных/in-memory нагрузок.
Встроенные chargeback/showback и cost dashboards (TCO-прозрачность, прогнозирование, возврат/reclaim неиспользуемых ресурсов).
Аппаратные улучшения/сетевой стек для AI
VCF 9.0 выравнивает работу «больших» AI-нагрузок на частной инфраструктуре:
Поддержка NVIDIA Blackwell (включая RTX PRO 6000 Blackwell Server Edition, B200, HGX с NVSwitch), GPUDirect RDMA/Storage, Enhanced DirectPath I/O - при этом сохраняются «классические» возможности vSphere (vMotion, HA, DRS, Live Patching).
Совместная работа с AMD: ROCm Enterprise AI и Instinct MI350 для задач fine-tuning/RAG/inference. Это не «плагин», а интегрированная часть VCF и экосистемы VMware Private AI Foundation with NVIDIA.
Как это интегрируется в вашм бизнес-процессы
Типовые сценарии, которые теперь проще закрывать «из коробки»:
Агенты поверх LLM: ускоренный старт с Agent Builder + подключение к корпоративным данным через индексирование/вектора.
RAG-потоки с политиками и аудитом: источники данных под управлением VCF, контроль доступа на уровне платформы, видимость (observability).
Доставка сервисов K8s: GitOps (Argo CD), сервис-меш (Istio), S3-объекты на vSAN для артефактов/данных.
Лицензирование/доставка и пути обновления
GA: VCF 9.0 доступен с 17 июня 2025.
Службы Private AI Services обещаны как часть подписки VCF 9.0 в Q1 FY26 от Broadcom.
Официальный документ с фичами и путями миграции VCF <-> VVF 9.0 доступен тут.
Вывод
VCF 9.0 — это не просто «еще одна» версия с оптимизациями. За счет включения Private AI Services в базовую платформу и сдвига на «one interface to operate/consume», VCF превращает AI-нагрузки в основу частного облака, сохраняя корпоративные политики, комплаенс и привычные SRE-процессы — от GPU до GitOps.
Оптимальная ИТ-инфраструктура характеризуется способностью поддерживать растущее количество рабочих нагрузок со временем и управлять колебаниями требований к ресурсам в реальном времени при сохранении максимальной производительности. VMware Cloud Foundation 9 облегчает внедрение облачной операционной модели в масштабах организации, тем самым ускоряя гибкость ИТ, повышая масштабируемость инфраструктуры, улучшая безопасность и снижая совокупную стоимость владения.
Data Services Manager (DSM) 9.0 теперь доступен, и организации стремятся понять, как использование этого дополнения к VMware Cloud Foundation (VCF) может помочь им в реализации решения DBaaS в локальной среде. В этом посте будут рассмотрены убедительные преимущества DSM, адаптированные для трех различных ролей: администратора, DBA и конечного пользователя/разработчика.
Преимущества DSM для администратора виртуальной инфраструктуры
Контроль размещения и отказоустойчивости
Прежде всего, этот продукт разработан с учетом требований администратора виртуальной инфраструктуры. Цель была помочь ему контролировать «разрастание данных» и сохранять контроль над размещением баз данных и сервисов данных в инфраструктуре vSphere. Это достигается посредством конструкции DSM, называемой политикой инфраструктуры. Она определяет, какие вычислительные ресурсы, хранилище, сети и даже какая папка ВМ используются для размещения конкретной базы данных. Это не только упрощает общее управление и использование инфраструктуры, но также помогает с контролем лицензирования, прогнозированием, биллингом и т. д. Такое размещение и контроль становятся еще более детализированными с VCF 9.0, где DSM может использовать политику инфраструктуры на основе пространства имен vSphere для развертывания баз данных и сервисов данных. Администратор создает пространства имен vSphere в Supervisor. Как администратор vSphere, он устанавливает лимиты на CPU, память и хранилище в пространстве имен vSphere.
Через политику инфраструктуры администратор также может определить отказоустойчивость базы данных. В то время как DBA может выбрать, будет ли база данных автономной (один узел) или кластерной (три узла), политика инфраструктуры определит размещение кластерной базы данных с точки зрения vSphere. По умолчанию DSM разместит три виртуальные машины кластерной базы данных на разных хостах ESX в одном кластере vSphere. Однако администратор также может создать межкластерную политику инфраструктуры, которая, будучи выбранной DBA, разместит разные узлы одного и того же кластера базы данных в разных кластерах vSphere, обеспечивая еще более высокий уровень доступности.
Видимость и аналитика
Хотя DSM имеет собственный интерфейс и API, не хотелось бы, чтобы администратор «переключался» между разными интерфейсами при мониторинге баз данных и сервисов данных, развернутых DSM на vSphere. Поэтому VMware интегрировала в клиент vSphere возможность просмотра сведений о базах данных и сервисах данных. С одного взгляда администратор может увидеть список развернутых баз данных, имя экземпляра базы, тип движка (Postgres, MySQL, MS SQL) в клиенте vSphere, а также статус БД, версию, уровень оповещений, число узлов, отказоустойчивость, политику инфраструктуры, политику хранения и т. д. Администраторы могут перейти к более детализированному просмотру и увидеть соответствующее имя виртуальной машины, сведения о размещении, а также использование CPU, памяти и дисков. Хотя это само по себе полезно для администратора, это также чрезвычайно полезно для обсуждений между администраторами и DBA по всем аспектам инфраструктуры, потребляемой базой данных, когда требуется понять использование ресурсов, производительность, масштабирование и другие характеристики. Пример такого представления приведен ниже.
Интеграция с vSphere и VMware Cloud Foundation
DSM интегрируется с основными инфраструктурными продуктами vSphere. В предыдущем параграфе мы упомянули, что администратор может просматривать сведения о базах данных через клиент vSphere. Однако также имеется интеграция с Aria Automation 8.x для тех клиентов, которые хотят использовать этот уровень интеграции. DSM поставляется с пользовательским ресурсом для Aria Automation, который после установки создает элемент каталога сервисов для поддержки DBaaS. DSM 9.0 также интегрируется с VCF Automation. Администраторы могут создавать политики службы данных и назначать эти политики различным организациям для полноценного multitenant опыта DBaaS.
Аналогично осуществляется интеграция с Aria Operations, куда DSM и соответствующие базы данных могут отправлять свои метрики. За последние несколько лет была проделана работа по этим интеграциям, включая создание ряда стандартных панелей мониторинга для различных баз данных. Также в версии VCF 9.0 значительно улучшили мониторинг баз данных - теперь все метрики отправляются в VCF Operations. Более того, метрики теперь могут отправляться из DSM 9.0 в эндпоинт Prometheus для тех клиентов, которые хотят это использовать.
Наконец, в этой секции выделим еще одну интеграцию — с Aria Operations for Logs. В один шаг DSM может отправлять все журналы как из самого DSM-апплаенса, так и из всех его баз данных в единую целевую точку. Эти журналы могут отправляться на любой SYSLOG-эндпоинт.
Все вышеперечисленные точки интеграции должны быть полезны для администраторов, использующих полный стек VCF.
Поддержка
Поддержка Broadcom охватывает управление жизненным циклом движков данных, управляемых DSM, включая развертывание, обновление ОС и программного обеспечения базы данных, масштабирование и кластеризацию. Поддержка самого движка PostgreSQL или MySQL, включая, но не ограничиваясь исправлением ошибок, проблемами производительности и устранением уязвимостей, осуществляется сообществом upstream, при этом Broadcom оказывает содействие по принципу "best-effort".
Кроме того, VMware работает с сообществом с открытым исходным кодом, чтобы предоставить полноценное исправление downstream для любых ошибок, обнаруженных клиентами. Хотя VMware не может гарантировать, когда конкретное исправление будет доступно в какой-либо из баз данных с открытым исходным кодом, они могут создавать пользовательские сборки с исправлениями, которые еще не доступны в версиях open source. Это распространенная модель поддержки для продуктов с открытым исходным кодом, и многие поставщики DBaaS используют ту же модель. Это должно дать клиентам уверенность при выборе DSM для их DBaaS решения.
Преимущества DSM для DBA
Теперь сосредоточимся на DBA и тех преимуществах, которые DSM приносит этой роли.
Интуитивно понятный интерфейс для управления парком БД
DSM предоставляет DBA единую панель управления, которая позволяет легко управлять всем парком баз данных. Ниже показана страница по умолчанию для администраторов DSM с различными параметрами управления и конфигурации.
Управление жизненным циклом
Команда DSM регулярно предоставляет обновления для DSM. Это включает обновления для виртуального модуля DSM, гостевой ОС, используемой узлами базы данных, версий Kubernetes в этих узлах, а также собственно самих баз данных. Единственное, что требуется от DBA — загрузить и подготовить обновление. Как для виртуального модуля, так и для баз данных доступны окна обслуживания. Если обновление подготовлено, и наступает окно (обычно в ночь с субботы на воскресенье), обновление применяется автоматически. Никому не нужно вручную управлять жизненным циклом ОС виртуальных машин или кластера K8s — DSM делает это автоматически. Этот аспект часто упускается при сравнении DSM с другими решениями DBaaS.
Еще один важный момент — DSM теперь умеет обновлять как основные (major), так и минорные версии базы данных. Хотя при мажорный обновлениях DBA должен проявлять осторожность (например, проверить совместимость расширений), наличие такой возможности является значительным преимуществом.
Автоматизированные резервные копии и восстановление к точке во времени
Как и управление жизненным циклом, резервное копирование может быть автоматически настроено на этапе развертывания базы данных. Если эта опция включена, DSM начнет выполнять резервные копии сразу после включения базы данных. По умолчанию для Postgres раз в неделю выполняется полный бэкап. Ежедневные бэкапы выполняются каждый день, а журналы WAL отправляются каждые 5 минут или по достижении 16 МБ — что произойдет раньше. Для MySQL и MS SQL Server существуют собственные расписания по умолчанию. Благодаря такому автоматизированному расписанию резервного копирования доступны восстановления к точке во времени для всех баз данных.
Масштабирование — In / Out / Up / Down
DSM позволяет DBA легко масштабировать топологии баз данных — от автономного узла до трехузлового кластера и обратно. Также допускается вертикальное масштабирование, путем смены класса виртуальной машины, что увеличивает доступные CPU и память. И наоборот — если ресурсы остаются неиспользованными, DBA может уменьшить класс ВМ и сократить потребление ресурсов. Это особенно полезно, например, для закрытия месяца, квартала или во время “Black Friday”, когда базе данных временно требуются дополнительные ресурсы. После окончания «пика» ресурсы можно освободить.
Клонирование
DSM позволяет DBA создавать клоны базы данных, если возникает такая необходимость. Это полезно для тестовых и девелоперских сред, когда разработчики хотят запускать запросы на «живых» данных, не затрагивая продуктивную базу.
Интеграция с LDAPS
DSM поддерживает защищенный LDAP как для доступа к самому DSM, так и к базам данных. Это делает назначение прав доступа более безопасным и удобным. При развертывании базы данных DBA может выбрать интеграцию с Directory Service и затем с помощью простого оператора GRANT предоставить LDAP-пользователям доступ к базе. Кроме того, DSM поддерживает защищенный LDAP и для собственного UI, что позволяет пользователям и разработчикам (при наличии прав) самостоятельно создавать базы данных через DSM-интерфейс. Поддерживаются как ticket-based, так и self-service подходы.
Управление сертификатами
Для обеспечения защищенного доступа к базе данных необходимы сертификаты. DSM предоставляет два варианта — использовать собственные самоподписанные сертификаты DSM или загрузить пользовательские сертификаты. DBA может применить сертификаты как при создании базы, так и после ее развертывания. UI и API DSM делают процесс добавления сертификатов очень простым. С учетом современных требований безопасности — это крайне важная функция.
Аудит и оповещения
DSM предоставляет различные механизмы для оповещений, а также встроенные функции в UI. Оповещения могут отправляться по электронной почте (SMTP), а также через webhook-механизм в сторонние системы, такие как ServiceNow или Slack. Таким образом, DBA-команда никогда не пропустит важное событие.
Для целей соответствия требованиям, DSM ведет аудит событий, который DBA может быстро просмотреть. В версии DSM 9.0 журналы аудита также передаются на настроенную систему получения логов.
Высокая отказоустойчивость
Хотя это может показаться зоной ответственности администратора, именно DBA выбирает нужный уровень отказоустойчивости при создании базы. Эти параметры управляются через инфраструктурные и storage-политики. Как упоминалось ранее, кластерные базы могут быть размещены либо в одном кластере vSphere, либо распределены по разным кластерам. DBA выбирает нужный вариант, выбирая соответствующую политику.
Шифрование
Для шифрования можно использовать функцию VM Crypt, что позволяет шифровать отдельные базы данных. Это определяется в политике хранения, входящей в инфраструктурную политику. Альтернативно можно шифровать весь datastore (например, vSAN), и тогда любая база, размещенная на нем, будет автоматически зашифрована. Оба подхода поддерживаются DSM.
Отказоустойчивость и репликация
DBA может использовать репликацию для удаленной защиты базы. При наличии нескольких сред vSphere вторичный узел Postgres может быть размещен в другой среде vSphere с другим экземпляром DSM. В UI доступны элементы управления для повышения вторичного узла в первичный и наоборот. В случае потери целой среды vSphere можно выполнить восстановление баз данных в другую среду и продолжить работу.
Host-based access при развертывании
Файл pg_hba.conf в Postgres определяет, какие пользователи из каких сетей могут обращаться к базе. Через UI DSM DBA может заранее задать правила доступа при развертывании, не заходя в базу после ее создания. Это предотвращает ситуацию, когда база находится в «незащищенном» состоянии, пока эти правила не будут вручную настроены.
Расширенные параметры при развертывании
Аналогично предыдущему пункту, DBA может задать расширенные параметры при создании базы, не выполняя это как отдельный пост-шаг. Это сокращает время развертывания.
Защита от удаления
Пользователи DSM могут восстановить базу данных после ее удаления. Период хранения удаленной базы составляет 30 дней, но может быть уменьшен или увеличен при необходимости.
Преимущества DSM для конечного пользователя/разработчика
Одной из основных задач DSM является обеспечение модели самообслуживания DBaaS. Поэтому DSM предоставляет конечным пользователям и разработчикам простой механизм для запроса и доступа к базам данных. Рассмотрим эти возможности далее.
Интуитивно понятный интерфейс
Пользователи DSM получают очень простой интерфейс, позволяющий легко создавать, обновлять и удалять базы данных по мере необходимости. Они не видят настроек конфигурации и не видят базы данных других пользователей. Для тех конечных пользователей, которые предпочитают UI для развертывания баз, это интуитивно понятный и простой процесс.
Kubernetes и REST API
VMware понимает, что многие разработчики предпочитают не использовать пользовательский интерфейс. В некоторых случаях развертывание базы данных является частью более крупного CI/CD-пайплайна для тестирования. В связи с этим DSM предоставляет как API для Kubernetes, так и REST API. Это позволяет автоматизировать развертывание баз данных через DSM. API доступны на официальном сайте DSM API.
Развертывание баз DSM из удалённых K8s-кластеров
Многие разработчики уже используют Kubernetes для разработки приложений. Эти кластеры могут быть ограничены по ресурсам, например, использовать только локальное хранилище. Кроме того, SRE-команды сталкиваются с проблемой того, что разработчики создают «неконтролируемые» базы данных и сервисы данных, что приводит к конфликтам по ресурсам и вопросам соответствия. Благодаря Consumption Operator в DSM разработчики могут создавать собственные базы данных DSM на инфраструктуре vSphere и подключаться к ним из своих Kubernetes-кластеров.
Итог
Data Services Manager приносит много полезных функций в VCF. DSM предоставляет DBaaS-решение для VCF с той же поддержкой, что и сам VCF. DSM уже работает в производственной среде и в масштабах, управляемых Broadcom IT на протяжении последнего года (вся разработка Broadcom использует DBaaS через DSM на VCF). У Broadcom также есть множество крупных клиентов, реализующих аналогичные сценарии. Надеемся, этот обзор преимуществ DSM был для вас полезен, и вы рассмотрите возможность использования его в своей среде VCF.
Недавно компания VMware опубликовала полезный для администраторов документ «vSphere 9.0 Performance Best Practices» с указанием ключевых рекомендаций по обеспечению максимальной производительности гипервизора ESX и инфраструктуры управления vCenter.
Документ охватывает ряд аспектов, начиная с аппаратных требований и заканчивая тонкой настройкой виртуальной инфраструктуры. Некоторые разделы включают не всем известные аспекты тонкой настройки:
Настройки BIOS: рекомендуется включить AES-NI, правильно сконфигурировать энергосбережение (например, «OS Controlled Mode»), при необходимости отключить некоторые C-states в особо чувствительных к задержкам приложениях.
vCenter и Content Library: советуют минимизировать автоматические скриптовые входы, использовать группировку vCenter для повышения синхронизации, хранить библиотеку контента на хранилищах с VAAI и ограничивать сетевую нагрузку через глобальный throttling.
Тонкое администрирование: правила доступа, лимиты, управление задачами, патчинг и обновления (включая рекомендации по BIOS и live scripts) и прочие глубокие настройки.
Отличия от версии для vSphere 8 (ESX и vCenter)
Аппаратные рекомендации
vSphere 8 предоставляет рекомендации по оборудованию: совместимость, минимальные требования, использование PMem (Optane, NVDIMM-N), vPMEM/vPMEMDisk, VAAI, NVMe, сетевые настройки, BIOS-опции и оптимизации I/O и памяти.
vSphere 9 добавляет новые аппаратные темы: фокус на AES-NI, snoop-режимах, NUMA-настройках, более гибком управлении энергопотреблением и безопасности на уровне BIOS.
vMotion и миграции
vSphere 8: введение «Unified Data Transport» (UDT) для ускорения холодных миграций и клонирования (при поддержке обеих сторон). Также рекомендации для связки encrypted vMotion и vSAN.
vSphere 9: больше внимания уделяется безопасности и производительности на стороне vCenter и BIOS, но UDT остаётся ключевым механизмом. В анонсах vSphere 9 в рамках Cloud Foundation акцент сделан на улучшенном управлении жизненным циклом и live patching.
Управление инфраструктурой
vSphere 8: рекомендации по vSphere Lifecycle Manager, UDT, обновлению vCenter и ESXi, GPU профили (в 8.0 Update 3) — включая поддержку разных vGPU, GPU Media Engine, dual DPU и live patch FSR.
vSphere 9 / VMware Cloud Foundation 9.0: новый подход к управлению жизненным циклом – поддержка live patch для vmkernel, NSX компонентов, более мощные «монстр-ВМ» (до 960 vCPU), direct upgrade с 8-й версии, image-based lifecycle management.
Работа с памятью
vSphere 8: рекомендации для Optane PMem, vPMEM/vPMEMDisk, управление памятью через ESXi.
vSphere 9 (через Cloud Foundation 9.0): внедрён memory tiering, позволяющий увеличить плотность ВМ в 2 раза при минимальной потере производительности (5%) и снижении TCO до 40%, без изменений в гостевой ОС.
Документ vSphere 9.0 Performance Best Practices содержит обновлённые и расширенные рекомендации для платформы vSphere 9, уделяющие внимание аппаратному уровню (BIOS-настройки, безопасность), инфраструктурному управлению, а также новым подходам к памяти (главный из них - memory tiering).
Оптимальная ИТ-инфраструктура характеризуется способностью поддерживать растущее количество рабочих нагрузок со временем и управлять изменениями потребностей в ресурсах в режиме реального времени при сохранении максимальной производительности. VMware Cloud Foundation упрощает внедрение облачной операционной модели в большом масштабе, тем самым повышая гибкость ИТ, расширяя масштабируемость инфраструктуры, улучшая безопасность и снижая совокупную стоимость владения.
Современная инфраструктура требует эффективного уровня управления и эксплуатации, который охватывает полный контроль жизненного цикла компонентов, обеспечивает прозрачность затрат и предоставляет четкий обзор общей безопасности системы.
Ключевым компонентом стека VCF является решение VMware Cloud Foundation Operations, которое помогает организациям создавать, эксплуатировать и защищать инфраструктуру частного облака за счёт развертывания и поддержки компонентов на уровне всего парка, обеспечения единой видимости и повышенной производительности на всех уровнях — от рабочих нагрузок до инфраструктуры, а также соблюдения нормативных и внутренних требований. Среди преимуществ — более быстрое достижение бизнес-результатов, улучшенное использование ресурсов, сокращение времени на устранение неполадок, предсказуемость затрат и безопасная, соответствующая требованиям среда. В рамках релиза VCF 9.0 ключевыми новыми и усовершенствованными возможностями VCF Operations являются:
Построение стека VCF
Управление парком ресурсов
Интегрированные операции
Управление затратами
Усиленная безопасность
Построение стека VCF
VMware Cloud Foundation 9.0 изменяет подход к развертыванию и построению инфраструктуры частного облака. Установщик VCF (VCF Installer) позволяет клиентам с лёгкостью создавать повторяемые участки инфраструктуры VCF, такие как кластеры приложений, для масштабирования парка ресурсов с целью повышения операционной эффективности и согласованности компонентов.
Парк VCF (VCF fleet) — это новый термин в VCF 9.0, обозначающий всю инфраструктуру, включая VCF Operations, VCF Automation, vCenter, NSX Manager, кластер vSphere, домены рабочих нагрузок и другие компоненты внутри VCF. Можно развернуть несколько экземпляров VCF, однако модули VCF Operations и VCF Automation существуют только в единственном экземпляре.
VCF 9.0 представляет новый мастер установки (Install wizard), который пошагово и интуитивно ведёт пользователя через процесс создания инфраструктуры. Можно развернуть новый парк ресурсов (fleet) или добавить инфраструктуру к уже существующей VCF-среде. Поддерживается настройка размера инфраструктуры и высокая доступность, а также возможность масштабирования частного облака с помощью JSON-файлов. Этот JSON можно сохранить для будущих развертываний и использовать в качестве шаблона. Перед установкой доступен предварительный просмотр и проверка параметров. После завершения работы установщика пользователь может войти в VCF Operations и приступить к работе.
Управление парком ресурсов (Fleet Management)
Предприятия, стремящиеся к масштабированию, нуждаются в согласованности своей инфраструктуры. Управление парком в VCF Operations помогает создавать, управлять и масштабировать инфраструктуру частного облака, обеспечивая единообразие всех компонентов. Оно объединяет доступ к ключевым административным задачам для инфраструктурных и управляющих компонентов. Некоторые из ключевых возможностей управления парком включают:
1. Управление лицензиями
VCF Operations теперь выступает в роли менеджера лицензий для всего стека VCF. С помощью VCF Operations лицензирование становится проще, оно унифицировано за счёт использования одного лицензионного файла. Ранее использовались длинные 25-символьные шестнадцатеричные ключи, которые нужно было вводить для каждого компонента отдельно. Теперь для каждого экземпляра VCF Operations используется один лицензионный файл, что облегчает распределение лицензий, отслеживание их использования и внесение изменений по ядрам и объёму хранилища vSAN (в TiB). Расширенные сервисы, такие как VMware Private AI Foundation с NVIDIA и дополнительное хранилище vSAN, также учитываются в этом файле. Другие дополнения по-прежнему используют традиционные лицензионные ключи.
2. Единый вход и централизованное управление идентификацией
VCF Operations обеспечивает поддержку единого входа (SSO) для VCF и всех экземпляров vCenter в парке. VCF 9.0 упрощает и модернизирует механизм SSO, предоставляя простое управление источниками идентификации, что снижает операционную сложность и повышает контроль над доступом благодаря гибкой настройке. Также возможно применять настройки клиента SSO из VCF Operations к отдельным компонентам. Система поддерживает различные решения идентификации, включая Active Directory Federation Services, Azure AD, OKTA, Ping и OAuth 2.0.
3. Управление сертификатами и паролями
VCF 9.0 внедряет централизованное управление сертификатами в VCF Operations, обеспечивая упрощённый пользовательский опыт во всей среде VCF. Эта функция позволяет выполнять обновления сертификатов без сбоев, автоматически продлевать их с помощью нескольких удостоверяющих центров (CA), а также импортировать внешне подписанные сертификаты. В результате упрощается администрирование, усиливаются меры безопасности и повышается соответствие требованиям.
Централизованная панель управления обеспечивает упрощённое управление паролями за счёт интеграции и консолидации. Система предоставляет полный обзор состояния паролей и функций управления, включая обновление, ротацию и уведомления об истечении срока действия.
4. Управление жизненным циклом
VCF 9.0 улучшает управление жизненным циклом, объединяя задачи второго дня (Day 2) в едином интерфейсе VCF Operations. Это упрощает контроль версий и оркестрацию обновлений, а также оптимизирует процессы для сокращения количества перезагрузок хостов и поддержки автоматизированных обновлений сразу в нескольких кластерах.
Интегрированные операции
Мониторинг работы всей среды может быть затруднён по многим причинам: отсутствие согласованности при анализе инфраструктурных данных (диагностика, журналы, метрики, сетевые потоки), усталость от множества оповещений, необходимость отслеживания сторонних решений и контейнеров, а также ограниченная гибкость при перемещении рабочих нагрузок в рамках виртуальной среды. Последний релиз VCF Operations решает эти проблемы, объединив ряд функций, ранее распределённых между разными продуктами.
1. VCF - здоровье и диагностика
Diagnostic Findings (диагностические выводы) — единое представление для отслеживания корреляции проблем во всей инфраструктуре за счёт сканирования и анализа известных сигнатур, с отображением текущих проблем на странице Active Findings.
VCF Health (мониторинг состояния) — даёт представление о текущем состоянии всех экземпляров vCenter, включая данные о подключениях, использовании ресурсов и сервисах, а также содержит функции общего назначения, такие как:
Операции с виртуальными машинами
vMotion
Управление снапшотами
Мониторинг состояния vSAN
2. Операции с хранилищем
Понимание использования хранилища имеет ключевое значение, и VCF Operations предоставляет мощные средства для анализа тенденций потребления ресурсов. В последнем релизе VCF Operations предлагает единое окно управления всеми аспектами хранения данных, включая инвентаризацию, конфигурацию и производительность в рамках VCF.
Инструмент Storage Distribution Insights отображает, как хранилище распределено между кластерами и рабочими нагрузками. Такой подробный обзор позволяет эффективно управлять ресурсами и быстро устранять проблемы, обеспечивая оптимальную производительность и использование хранилища.
3. Сетевые операции
VCF Operations теперь включает в себя интегрированные сетевые операции, обеспечивая полный обзор сети с возможностью мониторинга её состояния, анализа трафика и получения информации о приложениях. Система может автоматически обнаруживать бизнес-приложения и их уровни, чтобы настроить их отслеживание и начать мониторинг.
4. Интегрированные журналы
VCF Operations объединяет анализ файлов журналов всех компонентов, упрощая фильтрацию событий, визуализацию тенденций и ускоряя устранение неполадок из единой консоли. Оповещения на основе логов и настраиваемые панели мониторинга позволяют администраторам отслеживать динамику событий, выявлять аномалии и быстро диагностировать проблемы.
Функция Log Assist облегчает поиск и консолидацию журналов для эффективного проведения анализа первопричин (Root Cause Analysis, RCA) и ускоренного устранения неисправностей. В последнем релизе пользователи могут создавать архивные пакеты журналов и прикреплять их к обращениям в службу поддержки для более оперативного взаимодействия с техническими специалистами.
5. Расширяемость с использованием встроенного конструктора пакетов (Management Pack Builder)
В VCF Operations теперь доступен Management Pack Builder — встроенный конструктор пакетов управления, который предоставляет панели мониторинга, оповещения и метрики для всестороннего наблюдения и управления как компонентами VCF, так и сторонними устройствами.
6. Мониторинг Supervisor-кластера и Kubernetes-сервиса vSphere
VCF Operations теперь нативно поддерживает мониторинг Supervisor-кластера и VMware Kubernetes Service (VKS). С помощью агента Telegraf данные об инвентаризации и метриках передаются из Supervisor и VKS в VCF Operations.
Предоставляются готовые дэшборды и ключевые показатели производительности (KPI) для Supervisor-кластера, включая загрузку CPU, использование памяти, дисков, состояние узлов, подов и метрики на уровне контейнеров — всё это помогает в диагностике проблем с производительностью, связанными с Supervisor.
7. Планирование миграции рабочих нагрузок
Планирование миграции в VCF предлагает комплексный подход к масштабному переносу рабочих нагрузок, объединяя мощные возможности VCF Operations for Networks и VCF Operations HCX.
В этом релизе представлены основные функции этой возможности:
Пользователи могут легко и эффективно определить область миграции на основе приложений и выявить зависимости, чтобы не упустить важные компоненты. Обнаружение зависимостей приложений и сетей снижает риск ошибок при миграции и повышает надёжность.
Миграционные волны позволяют разбить процесс переноса на управляемые этапы. Это помогает сосредоточиться на небольших группах ресурсов, лучше планировать и выполнять миграцию поэтапно, снижая риски и сложность.
Информация об использовании памяти, ядер и хранилища помогает учитывать ограничения ресурсов и принимать обоснованные решения для их оптимального распределения в процессе миграции.
По мере развития функции планирования миграции пользователи получат более плавный и эффективный процесс переноса с чётким пониманием потребностей в ресурсах и зависимостях, что обеспечит более продуманный и управляемый подход к миграции рабочих нагрузок как внутри VCF, так и между VCF-средами.
Управление затратами
VCF Operations помогает оценить отдачу от инвестиций в VCF. Он отслеживает общую стоимость владения всей инфраструктурой, потенциальную и фактическую экономию благодаря рекомендациям, позволяя оценить эффективность и снижение затрат со временем.
Функции управления затратами в VCF Operations позволяют с высокой точностью отслеживать инфраструктурные расходы, затраты на лицензии и сопутствующие сервисы. Также поддерживаются механизмы showback и chargeback, позволяющие командам приложений понимать и контролировать стоимость используемой ими инфраструктуры.
ИТ-администраторы и провайдеры могут использовать:
Cost Drivers — распределение затрат по категориям
Pricing Policies — создание тарифных планов
Showback — отображение затрат по фактическому использованию
Chargeback — выставление счетов на основе заданных моделей ценообразования
1. Тарифные планы (Rate Cards)
Для точного выставления счетов арендаторам провайдеры могут создавать тарифные планы (rate cards), определяя стоимость единицы потребления ресурсов. Это позволяет единообразно рассчитывать затраты в соответствии с заданными условиями.
Тарифные планы можно настраивать по различным параметрам: вычислительные ресурсы (CPU и память), хранилище, сеть, гостевые ОС, теги, фиксированные единовременные расходы, корректирующие коэффициенты. Такая гибкость позволяет адаптировать цены как к техническому потреблению, так и к бизнес-модели.
Планы совместимы с последними лицензиями VCF и позволяют точно учитывать затраты по ядрам CPU и объёму хранилища.
2. Перерасчёт затрат (Chargeback)
Провайдеры могут получать детализированные данные о перерасчёте затрат с помощью улучшенных панелей, которые отображают расходы с разных управленческих уровней:
Обзор (Overview): сводная информация по затратам и ценам по организациям, регионам и запущенным ВМ.
Организации (Organizations): распределение затрат по организациям и региональным квотам.
Проекты (Projects): полное представление затрат и цен по проектам в VCF Automation с детализацией по пространствам имён и развёртываниям.
VCF Operations теперь поддерживает современные модели перерасчёта для IaaS как для провайдеров, так и для корпоративных команд приложений. Возможности перерасчёта интегрированы с новыми подходами к развёртыванию, реализуемыми через VCF Automation.
3. Анализ затрат (Cost Analysis)
Функции анализа затрат позволяют организациям получить чёткое представление о расходах на частное облако, выявить неэффективности и принимать обоснованные решения для оптимизации инвестиций.
Теперь пользователи могут быстро сравнивать метрики, например, стоимость эксплуатации и цену оказания услуг, в упрощённом интерфейсе. Это ускоряет получение аналитики, помогает оперативно выявлять наиболее затратные зоны и возможности для оптимизации всего за несколько кликов.
Усиленная безопасность
Возможности управления безопасностью обеспечивают комплексный обзор как инфраструктурного, так и пользовательского уровня, что снижает общую сложность с точки зрения рисков и поддерживает высокий уровень безопасности предприятия.
1. Дэшборды SecOps
Панель управления безопасностью (Security Operations Dashboard) предоставляет детализированный, real-time обзор аутентификации пользователей, прав доступа и состояния инфраструктуры, помогая проактивно управлять безопасностью во всех развертываниях VCF.
Инструмент охватывает ключевые аспекты защиты инфраструктуры, включая:
Шифрование хостов
Соответствие режимов работы хостов
Шифрование кластеров vSAN
Предупреждения о нарушениях CVE
Состояние сертификатов
Статус шифрования виртуальных машин
2. Отчётность по соответствию требованиям (Compliance Reporting)
VCF Operations предоставляет оповещения, политики и отчёты для проверки соответствия ресурсов VCF установленным стандартам, обеспечивая непрерывный контроль над соответствием, оперативные уведомления и поддержание общей политики безопасности инфраструктуры, снижая организационные и бизнес-риски.
В качестве бенчмарков могут использоваться следующие типы стандартов:
Предопределённые эталоны VMware, отслеживающие состояние среды в соответствии с рекомендациями по безопасности от VMware
Пользовательские политики, созданные вручную, для проверки среды на соответствие внутренним требованиям
Организации могут проактивно выявлять нарушения конфигурации и отклонения от соответствия требованиям, используя выбранные эталоны. Кроме того, благодаря интеграции VCF с инструментами управления конфигурациями от VMware или сторонних разработчиков возможна автоматическая коррекция нарушений соответствия.
В версии VCF 9.0 были добавлены новые комплекты соответствия для:
CIS (vSphere 8.0)
NIST SP 800-171
NIST SP 800-53 R5
А также обновлены средства проверки для:
HIPAA
PCI DSS v4.0
ISO/IEC 27001:2022
Мы видим, как VCF Operations помогает клиентам модернизировать инфраструктуру. Он предоставляет функции, которые позволяют инфраструктуре VCF работать как единая автоматизированная система, помогая организациям достигать своих ИТ- и бизнес-целей.
Дополнительные материалы
Release notes -
подробная информация о новых возможностях
Тестовая лаборатория: попробуйте VCF 9.0 в действии в новых лабах Hands-on Lab — What’s New in VMware Cloud Foundation 9.0 – Operations. Оцените возможности мониторинга, диагностики, анализа сетевых потоков, расширенного управления хранилищем, безопасности и прозрачности затрат.
Новая версия платформы VMware Cloud Foundation 9.0, включающая компоненты виртуализации серверов и хранилищ VMware vSphere 9.0, а также виртуализации сетей VMware NSX 9, привносит не только множество улучшений, но и устраняет ряд устаревших технологий и функций. Многие возможности, присутствовавшие в предыдущих релизах ESX (ранее ESXi), vCenter и NSX, в VCF 9 объявлены устаревшими (deprecated) или полностью удалены (removed). Это сделано для упрощения архитектуры, повышения безопасности и перехода на новые подходы к архитектуре частных и публичных облаков. Ниже мы подробно рассмотрим, каких функций больше нет во vSphere 9 (в компонентах ESX и vCenter) и NSX 9, и какие альтернативы или рекомендации по миграции существуют для администраторов и архитекторов.
Почему важно знать об удалённых функциях?
Новые релизы часто сопровождаются уведомлениями об устаревании и окончании поддержки прежних возможностей. Игнорирование этих изменений может привести к проблемам при обновлении и эксплуатации. Поэтому до перехода на VCF 9 следует проанализировать, используете ли вы какие-либо из перечисленных ниже функций, и заранее спланировать отказ от них или переход на новые инструменты.
VMware vSphere 9: удалённые и устаревшие функции ESX и vCenter
В VMware vSphere 9.0 (гипервизор ESX 9.0 и сервер управления vCenter Server 9.0) прекращена поддержка ряда старых средств администрирования и внедрены новые подходы. Ниже перечислены основные функции, устаревшие (подлежащие удалению в будущих версиях) или удалённые уже в версии 9, а также рекомендации по переходу на современные альтернативы:
vSphere Auto Deploy (устарела) – сервис автоматического развертывания ESXi-хостов по сети (PXE-boot) объявлен устаревшим. В ESX 9.0 возможность Auto Deploy (в связке с Host Profiles) будет удалена в одном из следующих выпусков линейки 9.x.
Рекомендация: если вы использовали Auto Deploy для бездискового развёртывания хостов, начните планировать переход на установку ESXi на локальные диски либо использование скриптов для автоматизации установки. В дальнейшем управление конфигурацией хостов следует осуществлять через образы vLCM и vSphere Configuration Profiles, а не через загрузку по сети.
vSphere Host Profiles (устарела) – механизм профилей хоста, позволявший применять единые настройки ко многим ESXi, будет заменён новой системой конфигураций. Начиная с vCenter 9.0, функциональность Host Profiles объявлена устаревшей и будет полностью удалена в будущих версиях.
Рекомендация: вместо Host Profiles используйте vSphere Configuration Profiles, позволяющие управлять настройками на уровне кластера. Новый подход интегрирован с жизненным циклом vLCM и обеспечит более надежную и простую поддержку конфигураций.
vSphere ESX Image Builder (устарела) – инструмент для создания кастомных образов ESXi (добавления драйверов и VIB-пакетов) больше не развивается. Функциональность Image Builder фактически поглощена возможностями vSphere Lifecycle Manager (vLCM): в vSphere 9 вы можете создавать библиотеку образов ESX на уровне vCenter и собирать желаемый образ из компонентов (драйверов, надстроек от вендоров и т.д.) прямо в vCenter.
Рекомендация: для формирования образов ESXi используйте vLCM Desired State Images и новую функцию ESX Image Library в vCenter 9, которая позволит единообразно управлять образами для кластеров вместо ручной сборки ISO-файлов.
vSphere Virtual Volumes (vVols, устарела) – технология виртуальных томов хранения объявлена устаревшей с выпуском VCF 9.0 / vSphere 9.0. Поддержка vVols отныне будет осуществляться только для критических исправлений в vSphere 8.x (VCF 5.x) до конца их поддержки. В VCF/VVF 9.1 функциональность vVols планируется полностью удалить.
Рекомендация: если в вашей инфраструктуре используются хранилища на основе vVols, следует подготовиться к миграции виртуальных машин на альтернативные хранилища. Предпочтительно задействовать VMFS или vSAN, либо проверить у вашего поставщика СХД доступность поддержки vVols в VCF 9.0 (в индивидуальном порядке возможна ограниченная поддержка, по согласованию с Broadcom). В долгосрочной перспективе стратегия VMware явно смещается в сторону vSAN и NVMe, поэтому использование vVols нужно минимизировать.
vCenter Enhanced Linked Mode (устарела) – расширенный связанный режим vCenter (ELM), позволявший объединять несколько vCenter Server в единый домен SSO с общей консолью, более не используется во VCF 9. В vCenter 9.0 ELM объявлен устаревшим и будет удалён в будущих версиях. Хотя поддержка ELM сохраняется в версии 9 для возможности обновления существующих инфраструктур, сама архитектура VCF 9 переходит на иной подход: единое управление несколькими vCenter осуществляется средствами VCF Operations вместо связанного режима.
Рекомендация: при планировании VCF 9 откажитесь от развёртывания новых связанных групп vCenter. После обновления до версии 9 рассмотрите перевод существующих vCenter из ELM в раздельный режим с группированием через VCF Operations (который обеспечивает центральное управление без традиционного ELM). Функции, ранее обеспечивавшиеся ELM (единый SSO, объединённые роли, синхронизация тегов, общая точка API и пр.), теперь достигаются за счёт возможностей VCF Operations и связанных сервисов.
vSphere Clustering Service (vCLS, устарела) – встроенный сервис кластеризации, который с vSphere 7 U1 запускал небольшие служебные ВМ (vCLS VMs) для поддержки DRS и HA, в vSphere 9 более не нужен. В vCenter 9.0 сервис vCLS помечен устаревшим и подлежит удалению в будущем. Кластеры vSphere 9 могут работать без этих вспомогательных ВМ: после обновления появится возможность включить Retreat Mode и отключить развёртывание vCLS-агентов без какого-либо ущерба для функциональности DRS/HA.
Рекомендация: отключите vCLS на кластерах vSphere 9 (включив режим Retreat Mode в настройках кластера) – деактивация vCLS никак не влияет на работу DRS и HA. Внутри ESX 9 реализовано распределенное хранилище состояния кластера (embedded key-value store) непосредственно на хостах, благодаря чему кластер может сохранять и восстанавливать свою конфигурацию без внешних вспомогательных ВМ. В результате вы упростите окружение (больше никаких «мусорных» служебных ВМ) и избавитесь от связанных с ними накладных расходов.
ESX Host Cache (устарела) - в версии ESX 9.0 использование кэша на уровне хоста (SSD) в качестве кэша с обратной записью (write-back) для файлов подкачки виртуальных машин (swap) объявлено устаревшим и будет удалено в одной из будущих версий. В качестве альтернативы предлагается использовать механизм многоуровневой памяти (Memory Tiering) на базе NVMe. Memory Tiering с NVMe позволяет увеличить объём доступной оперативной памяти на хосте и интеллектуально распределять память виртуальной машины между быстрой динамической оперативной памятью (DRAM) и NVMe-накопителем на хосте.
Рекомендация: используйте функции Advanced Memory Tiering на базе NVMe-устройств в качестве второго уровня памяти. Это позволяет увеличить объём доступной памяти до 4 раз, задействуя при этом существующие слоты сервера для недорогого оборудования.
Память Intel Optane Persistent Memory (удалена) - в версии ESX 9.0 прекращена поддержка технологии Intel Optane Persistent Memory (PMEM). Для выбора альтернативных решений обратитесь к представителям вашего OEM-поставщика серверного оборудования.
Рекомендация:
в качестве альтернативы вы можете использовать функционал многоуровневой памяти (Memory Tiering), официально представленный в ESX 9.0. Эта технология позволяет добавлять локальные NVMe-устройства на хост ESX в качестве дополнительного уровня памяти. Дополнительные подробности смотрите в статье базы знаний VMware KB 326910.
Технология Storage I/O Control (SIOC) и балансировщик нагрузки Storage DRS (удалены) - в версии vCenter 9.0 прекращена поддержка балансировщика нагрузки Storage DRS (SDRS) на основе ввода-вывода (I/O Load Balancer), балансировщика SDRS на основе резервирования ввода-вывода (SDRS I/O Reservations-based load balancer), а также компонента vSphere Storage I/O Control (SIOC). Эти функции продолжают поддерживаться в текущих релизах 8.x и 7.x. Удаление указанных компонентов затрагивает балансировку нагрузки на основе задержек ввода-вывода (I/O latency-based load balancing) и балансировку на основе резервирования ввода-вывода (I/O reservations-based load balancing) между хранилищами данных (datastores), входящими в кластер хранилищ Storage DRS. Кроме того, прекращена поддержка активации функции Storage I/O Control (SIOC) на отдельном хранилище и настройки резервирования (Reservations) и долей (Shares) с помощью политик хранения SPBM Storage Policy. При этом первоначальное размещение виртуальных машин с помощью Storage DRS (initial placement), а также балансировка нагрузки на основе свободного пространства и политик SPBM Storage Policy (для лимитов) не затронуты и продолжают работать в vCenter 9.0.
Рекомендация: администраторам рекомендуется нужно перейти на балансировку нагрузки на основе свободного пространства и политик SPBM. Настройки резервирований и долей ввода-вывода (Reservations, Shares) через SPBM следует заменить альтернативными механизмами контроля производительности со стороны используемых систем хранения (например, встроенными функциями QoS). После миграции необходимо обеспечить мониторинг производительности, чтобы своевременно устранять возможные проблемы.
vSphere Lifecycle Manager Baselines (удалена) – классический режим управления патчами через базовые уровни (baselines) в vSphere 9 не поддерживается. Начиная с vCenter 9.0 полностью удалён функционал VUM/vLCM Baselines – все кластеры и хосты должны использовать только рабочий процесс управления жизненным циклом на базе образов (image-based lifecycle). При обновлении с vSphere 8 имеющиеся кластеры на baselines придётся перевести на работу с образами, прежде чем поднять их до ESX 9.
Рекомендация: перейдите от использования устаревших базовых уровней к vLCM images – желаемым образам кластера. vSphere 9 позволяет применять один образ к нескольким кластерам или хостам сразу, управлять соответствием (compliance) и обновлениями на глобальном уровне. Это упростит администрирование и устранит необходимость в ручном создании и применении множества baseline-профилей.
Integrated Windows Authentication (IWA, удалена) – в vCenter 9.0 прекращена поддержка интегрированной Windows-аутентификации (прямого добавления vCenter в домен AD). Вместо IWA следует использовать LDAP(S) или федерацию. VMware официально заявляет, что vCenter 9.0 более не поддерживает IWA, и для обеспечения безопасного доступа необходимо мигрировать учетные записи на Active Directory over LDAPS или настроить федерацию (например, через ADFS) с многофакторной аутентификацией.
Рекомендация: до обновления vCenter отключите IWA, переведите интеграцию с AD на LDAP(S), либо настройте VMware Identity Federation с MFA (эта возможность появилась начиная с vSphere 7). Это позволит сохранить доменную интеграцию vCenter в безопасном режиме после перехода на версию 9.
Локализации интерфейса (сокращены) – В vSphere 9 уменьшено число поддерживаемых языков веб-интерфейса. Если ранее vCenter поддерживал множество языковых пакетов, то в версии 9 оставлены лишь английский (US) и три локали: японский, испанский и французский. Все остальные языки (включая русский) более недоступны.
Рекомендация: администраторы, использующие интерфейс vSphere Client на других языках, должны быть готовы работать на английском либо на одной из трёх оставшихся локалей. Учебные материалы и документацию стоит ориентировать на английскую версию интерфейса, чтобы избежать недопонимания.
Общий совет по миграции для vSphere: заранее инвентаризуйте использование перечисленных функций в вашей инфраструктуре. Переход на vSphere 9 – удобный повод внедрить новые подходы: заменить Host Profiles на Configuration Profiles, перейти от VUM-бейзлайнов к образам, отказаться от ELM в пользу новых средств управления и т.д. Благодаря этому обновление пройдет более гладко, а ваша платформа будет соответствовать современным рекомендациям VMware.
Мы привели, конечно же, список только самых важных функций VMware vSphere 9, которые подверглись устареванию или удалению, для получения полной информации обратитесь к этой статье Broadcom.
VMware NSX 9: Устаревшие и неподдерживаемые функции
VMware NSX 9.0 (ранее известный как NSX-T) – компонент виртуализации сети в составе VCF 9 – также претерпел существенные изменения. Новая версия NSX ориентирована на унифицированную работу с VMware Cloud Foundation и отказывается от ряда старых возможностей, особенно связанных с гибкостью поддержки разных платформ. Вот ключевые технологии, не поддерживаемые больше в NSX 9, и как к этому адаптироваться:
Подключение физических серверов через NSX-Agent (удалено) – В NSX 9.0 больше не поддерживается развёртывание NSX bare-metal agent на физических серверах для включения их в оверлей NSX. Ранее такие агенты позволяли физическим узлам участвовать в логических сегментах NSX (оверлейных сетях). Начиная с версии 9, оверлейная взаимосвязь с физическими серверами не поддерживается – безопасность для физических серверов (DFW) остаётся, а вот L2-overlay connectivity убрана.
Рекомендация: для подключения физических нагрузок к виртуальным сетям NSX теперь следует использовать L2-мосты (bridge) на NSX Edge. VMware прямо рекомендует для новых подключений физических серверов задействовать NSX Edge bridging для обеспечения L2-связности с оверлеем, вместо установки агентов на сами серверы. То есть физические серверы подключаются в VLAN, который бриджится в логический сегмент NSX через Edge Node. Это позволяет интегрировать физическую инфраструктуру с виртуальной без установки NSX компонентов на сами серверы. Если у вас были реализованы bare-metal transport node в старых версиях NSX-T 3.x, их придётся переработать на схему с Edge-бриджами перед обновлением до NSX 9. Примечание: распределённый мост Distributed TGW, появившийся в VCF 9, также может обеспечить выход ВМ напрямую на ToR без Edge-узла, что актуально для продвинутых случаев, но базовый подход – через Edge L2 bridge.
Виртуальный коммутатор N-VDS на ESXi (удалён) – исторически NSX-T использовала собственный виртуальный коммутатор N-VDS для хостов ESXi и KVM. В NSX 9 эта технология более не применяется для ESX-хостов. Поддержка NSX N-VDS на хостах ESX удалена, начиная с NSX 4.0.0.1 (соответствует VCF 9). Теперь NSX интегрируется только с родным vSphere Distributed Switch (VDS) версии 7.0 и выше. Это означает, что все среды на ESX должны использовать конвергентный коммутатор VDS для работы NSX. N-VDS остаётся лишь в некоторых случаях: на Edge-нодах и для агентов в публичных облаках или на bare-metal Linux (где нет vSphere), но на гипервизорах ESX – больше нет.
Рекомендация: перед обновлением до NSX 9 мигрируйте все транспортные узлы ESXi с N-VDS на VDS. VMware предоставила инструменты миграции host switch (начиная с NSX 3.2) – ими следует воспользоваться, чтобы перевести существующие NSX-T 3.x host transport nodes на использование VDS. После перехода на NSX 9 вы получите более тесную интеграцию сети с vCenter и упростите управление, так как сетевые политики NSX привязываются к стандартному vSphere VDS. Учтите, что NSX 9 требует наличия vCenter для настройки сетей (фактически NSX теперь не работает автономно от vSphere), поэтому планируйте инфраструктуру исходя из этого.
Поддержка гипервизоров KVM и стороннего OpenStack (удалена) – NSX-T изначально позиционировался как мультигипервизорное решение, поддерживая кроме vSphere также KVM (Linux) и интеграцию с opensource OpenStack. Однако с выходом NSX 4.0 (и NSX 9) стратегия изменилась. NSX 9.0 больше не поддерживает гипервизоры KVM и дистрибутивы OpenStack от сторонних производителей. Поддерживается лишь VMware Integrated OpenStack (VIO) как исключение. Проще говоря, NSX сейчас нацелен исключительно на экосистему VMware.
Рекомендация: если у вас были развёрнуты политики NSX на KVM-хостах или вы использовали NSX-T совместно с не-VMware OpenStack, переход на NSX 9 невозможен без изменения архитектуры. Вам следует либо остаться на старых версиях NSX-T 3.x для таких сценариев, либо заменить сетевую виртуализацию в этих средах на альтернативные решения. В рамках же VCF 9 такая ситуация маловероятна, так как VCF подразумевает vSphere-стек. Таким образом, основное действие – убедиться, что все рабочие нагрузки NSX переведены на vSphere, либо изолировать NSX-T 3.x для специфичных нужд вне VCF. В будущем VMware будет развивать NSX как часть единой платформы, поэтому мультиплатформенные возможности урезаны в пользу оптимизации под vSphere.
NSX for vSphere (NSX-V) 6.x – не применяется – отдельно стоит упомянуть, что устаревшая платформа NSX-V (NSX 6.x для vSphere) полностью вышла из обращения и не входит в состав VCF 9. Её поддержка VMware прекращена еще в начале 2022 года, и миграция на NSX-T (NSX 4.x) стала обязательной. В VMware Cloud Foundation 4.x и выше NSX-V отсутствует, поэтому для обновления окружения старше VCF 3 потребуется заранее выполнить миграцию сетевой виртуализации на NSX-T.
Рекомендация: если вы ещё используете NSX-V в старых сегментах, необходимо развернуть параллельно NSX 4.x (NSX-T) и перенести сетевые политики и сервисы (можно с помощью утилиты Migration Coordinator, если поддерживается ваша версия). Только после перехода на NSX-T вы сможете обновиться до VCF 9. В новой архитектуре все сетевые функции будут обеспечиваться NSX 9, а NSX-V останется в прошлом.
Подводя итог по NSX: VMware NSX 9 сфокусирован на консолидации функций для частных облаков на базе vSphere. Возможности, выходящие за эти рамки (поддержка разнородных гипервизоров, агенты на физической базе и др.), были убраны ради упрощения и повышения производительности. Администраторам следует заранее учесть эти изменения: перевести сети на VDS, пересмотреть способы подключения физических серверов и убедиться, что все рабочие нагрузки, требующие NSX, работают в поддерживаемой конфигурации. Благодаря этому переход на VCF 9 будет предсказуемым, а новая среда – более унифицированной, безопасной и эффективной. Подготовившись к миграции от устаревших технологий на современные аналоги, вы сможете реализовать преимущества VMware Cloud Foundation 9.0 без длительных простоев и с минимальным риском для работы дата-центра.
Итоги
Большинство приведённых выше изменений официально перечислены в документации Product Support Notes к VMware Cloud Foundation 9.0 для vSphere и NSX. Перед обновлением настоятельно рекомендуется внимательно изучить примечания к выпуску и убедиться, что ни одна из устаревших функций, на которых зависит ваша инфраструктура, не окажется критичной после перехода. Следуя рекомендациям по переходу на новые инструменты (vLCM, Configuration Profiles, Edge Bridge и т.д.), вы обеспечите своей инфраструктуре поддерживаемость и готовность к будущим обновлениям в экосистеме VMware Cloud Foundation.
Итак, наконец-то начинаем рассказывать о новых возможностях платформы виртуализации VMware vSphere 9, которая является основой пакета решений VMware Cloud Foundation 9, о релизе которого компания Broadcom объявила несколько дней назад. Самое интересное - гипервизор теперь опять называется ESX, а не ESXi, который также стал последователем ESX в свое время :)
Управление жизненным циклом
Путь обновления vSphere
vSphere 9.0 поддерживает прямое обновление только с версии vSphere 8.0. Прямое обновление с vSphere 7.0 не поддерживается. vCenter 9.0 не поддерживает управление ESX 7.0 и более ранними версиями. Минимально поддерживаемая версия ESX, которую может обслуживать vCenter 9.0, — это ESX 8.0. Кластеры и отдельные хосты, управляемые на основе baseline-конфигураций (VMware Update Manager, VUM), не поддерживаются в vSphere 9. Кластеры и хосты должны использовать управление жизненным циклом только на основе образов.
Live Patch для большего числа компонентов ESX
Функция Live Patch теперь охватывает больше компонентов образа ESX, включая vmkernel и компоненты NSX. Это увеличивает частоту применения обновлений без перезагрузки. Компоненты NSX, теперь входящие в базовый образ ESX, можно обновлять через Live Patch без перевода хостов в режим обслуживания и без необходимости эвакуировать виртуальные машины.
Компоненты vmkernel, пользовательское пространство, vmx (исполнение виртуальных машин) и NSX теперь могут использовать Live Patch. Службы ESX (например, hostd) могут потребовать перезапуска во время применения Live Patch, что может привести к кратковременному отключению хостов ESX от vCenter. Это ожидаемое поведение и не влияет на работу запущенных виртуальных машин. vSphere Lifecycle Manager сообщает, какие службы или демоны будут перезапущены в рамках устранения уязвимостей через Live Patch. Если Live Patch применяется к среде vmx (исполнение виртуальных машин), запущенные ВМ выполнят быструю приостановку и восстановление (Fast-Suspend-Resume, FSR).
Live Patch совместим с кластерами vSAN. Однако узлы-свидетели vSAN (witness nodes) не поддерживают Live Patch и будут полностью перезагружаться при обновлении. Хосты, использующие TPM и/или DPU-устройства, в настоящее время не совместимы с Live Patch.
Создавайте кластеры по-своему с разным оборудованием
vSphere Lifecycle Manager поддерживает кластеры с оборудованием от разных производителей, а также работу с несколькими менеджерами поддержки оборудования (hardware support managers) в рамках одного кластера. vSAN также поддерживает кластеры с различным оборудованием.
Базовая версия ESX является неизменной для всех дополнительных образов и не может быть настроена. Однако надстройки от производителей (vendor addon), прошивка и компоненты в определении каждого образа могут быть настроены индивидуально для поддержки кластеров с разнородным оборудованием. Каждое дополнительное определение образа может быть связано с уникальным менеджером поддержки оборудования (HSM).
Дополнительные образы можно назначать вручную для подмножества хостов в кластере или автоматически — на основе информации из BIOS, включая значения Vendor, Model, OEM String и Family. Например, можно создать кластер, состоящий из 5 хостов Dell и 5 хостов HPE: хостам Dell можно назначить одно определение образа с надстройкой от Dell и менеджером Dell HSM, а хостам HPE — другое определение образа с надстройкой от HPE и HSM от HPE.
Масштабное управление несколькими образами
Образами vSphere Lifecycle Manager и их привязками к кластерам или хостам можно управлять на глобальном уровне — через vCenter, датацентр или папку. Одно определение образа может применяться к нескольким кластерам и/или отдельным хостам из единого централизованного интерфейса. Проверка на соответствие (Compliance), предварительная проверка (Pre-check), подготовка (Stage) и устранение (Remediation) также могут выполняться на этом же глобальном уровне.
Существующие кластеры и хосты с управлением на основе базовых конфигураций (VUM)
Существующие кластеры и отдельные хосты, работающие на ESX 8.x и использующие управление на основе базовых конфигураций (VUM), могут по-прежнему управляться через vSphere Lifecycle Manager, но для обновления до ESX 9 их необходимо перевести на управление на основе образов. Новые кластеры и хосты не могут использовать управление на основе baseline-конфигураций, даже если они работают на ESX 8. Новые кластеры и хосты автоматически используют управление жизненным циклом на основе образов.
Больше контроля над операциями жизненного цикла кластера
При устранении проблем (remediation) в кластерах теперь доступна новая возможность — применять исправления к подмножеству хостов в виде пакета. Это дополняет уже существующие варианты — обновление всего кластера целиком или одного хоста за раз.
Гибкость при выборе хостов для обновления
Описанные возможности дают клиентам гибкость — можно выбрать, какие хосты обновлять раньше других. Другой пример использования — если в кластере много узлов и обновить все за одно окно обслуживания невозможно, клиенты могут выбирать группы хостов и обновлять их поэтапно в несколько окон обслуживания.
Больше никакой неопределённости при обновлениях и патчах
Механизм рекомендаций vSphere Lifecycle Manager учитывает версию vCenter. Версия vCenter должна быть равной или выше целевой версии ESX. Например, если vCenter работает на версии 9.1, механизм рекомендаций не предложит обновление хостов ESX до 9.2, так как это приведёт к ситуации, где хосты будут иметь более новую версию, чем vCenter — что не поддерживается. vSphere Lifecycle Manager использует матрицу совместимости продуктов Broadcom VMware (Product Interoperability Matrix), чтобы убедиться, что целевой образ ESX совместим с текущей средой и поддерживается.
Упрощённые определения образов кластера
Компоненты vSphere HA и NSX теперь встроены в базовый образ ESX. Это делает управление их жизненным циклом и обеспечением совместимости более прозрачным и надёжным. Компоненты vSphere HA и NSX автоматически обновляются вместе с установкой патчей или обновлений базового образа ESX. Это ускоряет активацию NSX на кластерах vSphere, поскольку VIB-пакеты больше не требуется отдельно загружать и устанавливать через ESX Agent Manager (EAM).
Определение и применение конфигурации NSX для кластеров vSphere с помощью vSphere Configuration Profiles
Теперь появилась интеграция NSX с кластерами, управляемыми через vSphere Configuration Profiles. Профили транспортных узлов NSX (TNP — Transport Node Profiles) применяются с использованием vSphere Configuration Profiles. vSphere Configuration Profiles позволяют применять TNP к кластеру одновременно с другими изменениями конфигурации.
Применение TNP через NSX Manager отключено для кластеров с vSphere Configuration Profiles
Для кластеров, использующих vSphere Configuration Profiles, возможность применять TNP (Transport Node Profile) через NSX Manager отключена. Чтобы применить TNP с помощью vSphere Configuration Profiles, необходимо также задать:
набор правил брандмауэра с параметром DVFilter=true
настройку Syslog с параметром remote_host_max_msg_len=4096
Снижение рисков и простоев при обновлении vCenter
Функция Reduced Downtime Update (RDU) поддерживается при использовании установщика на базе CLI. Также доступны RDU API для автоматизации. RDU поддерживает как вручную настроенные топологии vCenter HA, так и любые другие топологии vCenter. RDU является рекомендуемым способом обновления, апгрейда или установки патчей для vCenter 9.0.
Обновление vCenter с использованием RDU можно выполнять через vSphere Client, CLI или API. Интерфейс управления виртуальным устройством (VAMI) и соответствующие API для патчинга также могут использоваться для обновлений без переустановки или миграции, однако при этом потребуется значительное время простоя.
Сетевые настройки целевой виртуальной машины vCenter поддерживают автоматическую конфигурацию, упрощающую передачу данных с исходного vCenter. Эта сеть автоматически настраивается на целевой и исходной виртуальных машинах vCenter с использованием адреса из диапазона Link-Local RFC3927 169.254.0.0/16. Это означает, что не требуется указывать статический IP-адрес или использовать DHCP для временной сети.
Этап переключения (switchover) может выполняться вручную, автоматически или теперь может быть запланирован на конкретную дату и время в будущем.
Управление ресурсами
Масштабирование объема памяти с более низкой стоимостью владения благодаря Memory Tiering с использованием NVMe
Memory Tiering использует устройства NVMe на шине PCIe как второй уровень оперативной памяти, что увеличивает доступный объем памяти на хосте ESX. Memory Tiering на базе NVMe снижает общую стоимость владения (TCO) и повышает плотность размещения виртуальных машин, направляя память ВМ либо на устройства NVMe, либо на более быструю оперативную память DRAM.
Это позволяет увеличить объем доступной памяти и количество рабочих нагрузок, одновременно снижая TCO. Также повышается эффективность использования процессорных ядер и консолидация серверов, что увеличивает плотность размещения рабочих нагрузок.
Функция Memory Tiering теперь доступна в производственной среде. В vSphere 8.0 Update 3 функция Memory Tiering была представлена в режиме технологического превью. Теперь же она стала доступна в режиме GA (General Availability) с выпуском VCF 9.0. Это позволяет использовать локально установленные устройства NVMe на хостах ESX как часть многоуровневой (tiered) памяти.
Повышенное время безотказной работы для AI/ML-нагрузок
Механизм Fast-Suspend-Resume (FSR) теперь работает значительно быстрее для виртуальных машин с поддержкой vGPU. Ранее при использовании двух видеокарт NVIDIA L40 с 48 ГБ памяти каждая, операция FSR занимала около 42 секунд. Теперь — всего около 2 секунд. FSR позволяет использовать Live Patch в кластерах, обрабатывающих задачи генеративного AI (Gen AI), без прерывания работы виртуальных машин.
Передача данных vGPU с высокой пропускной способностью
Канал передачи данных vGPU разработан для перемещения больших объемов данных и построен с использованием нескольких параллельных TCP-соединений и автоматического масштабирования до максимально доступной пропускной способности канала, обеспечивая прирост скорости до 3 раз (с 10 Гбит/с до 30 Гбит/с).
Благодаря использованию концепции "zero copy" количество операций копирования данных сокращается вдвое, устраняя узкое место, связанное с копированием, и дополнительно увеличивая пропускную способность при передаче.
vMotion с предкопированием (pre-copy) — это технология передачи памяти виртуальной машины на другой хост с минимальным временем простоя. Память виртуальной машины (как "холодная", так и "горячая") копируется в несколько проходов пока ВМ ещё работает, что устраняет необходимость полного чекпойнта и передачи всей памяти во время паузы, во время которой случается простой сервисов.
Улучшения в предкопировании холодных данных могут зависеть от характера нагрузки. Например, для задачи генеративного AI с большим объёмом статических данных ожидаемое время приостановки (stun-time) будет примерно:
~1 секунда для GPU-нагрузки объёмом 24 ГБ
~2 секунды для 48 ГБ
~22 секунды для крупной 640 ГБ GPU-нагрузки
Отображение профилей vGPU в vSphere DRS
Технология vGPU позволяет распределять физический GPU между несколькими виртуальными машинами, способствуя максимальному использованию ресурсов видеокарты.
В организациях с большим числом GPU со временем создаётся множество vGPU-профилей. Однако администраторы не могут легко просматривать уже созданные vGPU, что вынуждает их вручную отслеживать профили и их распределение по GPU. Такой ручной процесс отнимает время и снижает эффективность работы администраторов.
Отслеживание использования vGPU-профилей позволяет администраторам просматривать все vGPU во всей инфраструктуре GPU через удобный интерфейс в vCenter, устраняя необходимость ручного учёта vGPU. Это существенно сокращает время, затрачиваемое администраторами на управление ресурсами.
Интеллектуальное размещение GPU-ресурсов в vSphere DRS
В предыдущих версиях распределение виртуальных машин с vGPU могло приводить к ситуации, при которой ни один из хостов не мог удовлетворить требования нового профиля vGPU. Теперь же администраторы могут резервировать ресурсы GPU для будущего использования. Это позволяет заранее выделить GPU-ресурсы, например, для задач генеративного AI, что помогает избежать проблем с производительностью при развертывании таких приложений. С появлением этой новой функции администраторы смогут резервировать пулы ресурсов под конкретные vGPU-профили заранее, улучшая планирование ресурсов и повышая производительность и операционную эффективность.
Миграция шаблонов и медиафайлов с помощью Content Library Migration
Администраторы теперь могут перемещать существующие библиотеки контента на новые хранилища данных (datastore) - OVF/OVA-шаблоны, образы и другие элементы могут быть перенесены. Элементы, хранящиеся в формате VM Template (VMTX), не переносятся в целевой каталог библиотеки контента. Шаблоны виртуальных машин (VM Templates) всегда остаются в своем назначенном хранилище, а в библиотеке контента хранятся только ссылки на них.
Во время миграции библиотека контента перейдёт в режим обслуживания, а после завершения — снова станет активной. На время миграции весь контент библиотеки (за исключением шаблонов ВМ) будет недоступен. Изменения в библиотеке будут заблокированы, синхронизация с подписными библиотеками приостановлена.
vSphere vMotion между управляющими плоскостями (Management Planes)
Служба виртуальных машин (VM Service) теперь может импортировать виртуальные машины, находящиеся за пределами Supervisor-кластера, и взять их под своё управление.
Network I/O Control (NIOC) для vMotion с использованием Unified Data Transport (UDT)
В vSphere 8 был представлен протокол Unified Data Transport (UDT) для "холодной" миграции дисков, ранее выполнявшейся с использованием NFC. UDT значительно ускоряет холодную миграцию, но вместе с повышенной эффективностью увеличивается и нагрузка на сеть предоставления ресурсов (provisioning network), которая в текущей архитектуре использует общий канал с критически важным трафиком управления.
Чтобы предотвратить деградацию трафика управления, необходимо использовать Network I/O Control (NIOC) — он позволяет гарантировать приоритет управления даже при высокой сетевой нагрузке.
vSphere Distributed Switch 9 добавляет отдельную категорию системного трафика для provisioning, что позволяет применять настройки NIOC и обеспечить баланс между производительностью и стабильностью.
Provisioning/NFC-трафик: ресурсоёмкий, но низкоприоритетный
Provisioning/NFC-трафик (включая Network File Copy) является тяжеловесным и низкоприоритетным, но при этом использует ту же категорию трафика, что и управляющий (management), который должен быть легковесным и высокоприоритетным. С учетом того, что трафик provisioning/NFC стал ещё более агрессивным с внедрением NFC SOV (Streaming Over vMotion), вопрос времени, когда критически важный трафик управления начнёт страдать.
Существует договоренность с VCF: как только NIOC для provisioning/NFC будет реализован, можно будет включать NFC SOV в развёртываниях VCF. Это ускорит внедрение NFC SOV в продуктивных средах.
Расширение поддержки Hot-Add устройств с Enhanced VM DirectPath I/O
Устройства, которые не могут быть приостановлены (non-stunnable devices), теперь поддерживают Storage vMotion (но не обычный vMotion), а также горячее добавление виртуальных устройств, таких как:
vCPU
Память (Memory)
Сетевые адаптеры (NIC)
Примеры non-stunnable устройств:
Intel DLB (Dynamic Load Balancer)
AMD MI200 GPU
Гостевые ОС и рабочие нагрузки
Виртуальное оборудование версии 22 (Virtual Hardware Version 22)
Увеличен лимит vCPU до 960 на одну виртуальную машину
Поддержка новейших моделей процессоров от AMD и Intel
vTPM теперь поддерживает спецификацию TPM 2.0, версия 1.59.
ESX 9.0 соответствует TPM 2.0 Rev 1.59.
Это повышает уровень кибербезопасности, когда вы добавляете vTPM-устройство в виртуальную машину с версией 22 виртуального железа.
Новые vAPI для настройки гостевых систем (Guest Customization)
Представлен новый интерфейс CustomizationLive API, который позволяет применять спецификацию настройки (customization spec) к виртуальной машине в работающем состоянии (без выключения). Подробности — в последней документации по vSphere Automation API для VCF 9.0. Также добавлен новый API для настройки гостевых систем, который позволяет определить, можно ли применить настройку к конкретной ВМ, ещё до её применения.
В vSphere 9 появилась защита пространств имен (namespace) и поддержка Write Zeros для виртуальных NVMe. vSphere 9 вводит поддержку:
Namespace Write Protection - позволяет горячее добавление независимых непостоянных (non-persistent) дисков в виртуальную машину без создания дополнительных delta-дисков. Эта функция особенно полезна для рабочих нагрузок, которым требуется быстрое развёртывание приложений.
Write Zeros - для виртуальных NVMe-дисков улучшает производительность, эффективность хранения данных и дает возможности управления данными для различных типов нагрузок.
Безопасность, соответствие требованиям и отказоустойчивость виртуальных машин
Одним из частых запросов в последние годы была возможность использовать собственные сертификаты Secure Boot для ВМ. Обычно виртуальные машины работают "из коробки" с коммерческими ОС, но некоторые организации используют собственные ядра Linux и внутреннюю PKI-инфраструктуру для их подписи.
Теперь появилась прямая и удобная поддержка такой конфигурации — vSphere предоставляет механизм для загрузки виртуальных машин с кастомными сертификатами Secure Boot.
Обновлён список отозванных сертификатов Secure Boot
VMware обновила стандартный список отозванных сертификатов Secure Boot, поэтому при установке Windows на виртуальную машину с новой версией виртуального оборудования может потребоваться современный установочный образ Windows от Microsoft. Это не критично, но стоит иметь в виду, если установка вдруг не загружается.
Улучшения виртуального USB
Виртуальный USB — отличная функция, но VMware внесла ряд улучшений на основе отчётов исследователей по безопасности. Это ещё один веский аргумент в пользу того, чтобы поддерживать актуальность VMware Tools и версий виртуального оборудования.
Форензик-снапшоты (Forensic Snapshots)
Обычно мы стремимся к тому, чтобы снапшот ВМ можно было запустить повторно и обеспечить согласованность при сбое (crash-consistency), то есть чтобы система выглядела как будто питание отключилось. Большинство ОС, СУБД и приложений умеют с этим справляться.
Но в случае цифровой криминалистики и реагирования на инциденты, необходимость перезапускать ВМ заново отпадает — важнее получить снимок, пригодный для анализа в специальных инструментах.
Custom EVC — лучшая совместимость между разными поколениями CPU
Теперь вы можете создавать собственный профиль EVC (Enhanced vMotion Compatibility), определяя набор CPU- и графических инструкций, общих для всех выбранных хостов. Это решение более гибкое и динамичное, чем стандартные предустановленные профили EVC.
Custom EVC позволяет:
Указать хосты и/или кластеры, для которых vCenter сам рассчитает максимально возможный общий набор инструкций
Применять полученный профиль к кластерам или отдельным ВМ
Для работы требуется vCenter 9.0 и поддержка кластеров, содержащих хосты ESX 9.0 или 8.0. Теперь доступно более эффективное использование возможностей CPU при различиях между моделями - можно полнее использовать функции процессоров, даже если модели немного отличаются. Пример: два процессора одного поколения, но разных вариантов:
CPU-1 содержит функции A, B, D, E, F
CPU-2 содержит функции B, C, D, E, F
То есть: CPU-1 поддерживает FEATURE-A, но не FEATURE-C, CPU-2 — наоборот.
Custom EVC позволяет автоматически выбрать максимальный общий набор функций, доступный на всех хостах, исключая несовместимости:
В vSphere 9 появилась новая политика вычислений: «Limit VM placement span plus one host for maintenance» («ограничить размещение ВМ числом хостов плюс один для обслуживания»).
Эта политика упрощает соблюдение лицензионных требований и контроль использования лицензий. Администраторы теперь могут создавать политики на основе тегов, которые жестко ограничивают количество хостов, на которых может запускаться группа ВМ с лицензируемым приложением.
Больше не нужно вручную закреплять ВМ за хостами или создавать отдельные кластеры/хосты. Теперь администратору нужно просто:
Знать, сколько лицензий куплено.
Знать, на скольких хостах они могут применяться.
Создать политику с указанием числа хостов, без выбора конкретных.
Применить эту политику к ВМ с нужным тегом.
vSphere сама гарантирует, что такие ВМ смогут запускаться только на разрешённом числе хостов. Всегда учитывается N+1 хост в запас для обслуживания. Ограничение динамическое — не привязано к конкретным хостам.
Полный список новых возможностей VMware vSphere 9 также приведен в Release Notes.
Продолжаем рассказывать о российском ПО в сфере серверной виртуализации. Numa vServer — российская платформа серверной виртуализации корпоративного уровня, разработанная компанией «НумаТех». Она предназначена для создания защищённых виртуальных инфраструктур и соответствует требованиям информационной безопасности, установленным ФСТЭК России.
Архитектура и технологии
В основе Numa vServer лежит гипервизор первого типа на базе Xen, доработанный более чем в 300 аспектах для повышения безопасности, надёжности и производительности. Платформа устанавливается напрямую на аппаратное обеспечение (bare-metal), что исключает необходимость в хостовой операционной системе и обеспечивает высокую производительность и безопасность.
Безопасность и сертификация
Numa vServer сертифицирован ФСТЭК России по 4 уровню доверия и 4 классу защиты (сертификат № 4580 от 23.09.2022) . Это позволяет использовать платформу в государственных информационных системах, системах обработки персональных данных, АСУ ТП и критически важных объектах.
Ключевые функции безопасности:
Изолированная среда исполнения управляющей ВМ (Domain 0).
Мандатный контроль доступа и зонирование.
Контроль целостности конфигураций, журналов и образов ВМ.
Журналирование действий пользователей и фильтрация потоков данных.
Поддержка многофакторной аутентификации и интеграция с LDAP/Active Directory.
Функциональные возможности
Кластеризация и высокая доступность: поддержка до 64 серверов в одном пуле с возможностью автоматической миграции ВМ при сбоях.
Резервное копирование и восстановление: полные и дельта-копии, снэпшоты, репликация, поддержка протоколов NFS, SMB/CIFS, S3.
Импорт/экспорт ВМ: поддержка форматов VMware, Citrix, VirtualBox.
Управление через Numa Collider: веб-интерфейс для администрирования, мониторинга и настройки виртуальной инфраструктуры.
Интеграция с OpenStack и CloudStack: поддержка инструментов IaC, таких как Packer и Terraform.
Виртуализация GPU: возможность делить графический адаптер между несколькими ВМ с поддержкой 3D-графики.
Системные требования
Numa vServer предъявляет низкие требования к оборудованию, что позволяет использовать его на серверах возрастом более 10 лет.
Минимальные требования:
Процессор: 2 ядра, 1.5 ГГц.
Оперативная память: 4 ГБ.
Диск: 128 ГБ.
Сетевой адаптер: 1 порт, 100 Мбит/с.
Рекомендуемые характеристики:
Процессор: 4–8 ядер, 2.5 ГГц с поддержкой Intel-VT или AMD-V.
Оперативная память: 16 ГБ с поддержкой ECC.
Диск: 750 ГБ.
Сетевой адаптер: 2 порта, 1 Гбит/с.
Лицензирование и поддержка
Лицензирование Numa vServer осуществляется по количеству физических процессоров. В базовую лицензию входит редакция «Начальная» консоли управления Numa Collider. Доступны также расширенные редакции с дополнительным функционалом, такими как балансировка нагрузки, программно-определяемые сети и расширенные возможности резервного копирования.
Применение и преимущества
Numa vServer подходит для организаций, стремящихся к импортозамещению и обеспечению информационной безопасности. Платформа может использоваться для:
Создания защищённых частных, публичных или гибридных облаков.
Виртуализации отдельных серверных ролей.
Обеспечения высокой доступности критически важных систем.
Выполнения требований регуляторов в области защиты информации.
Преимущества:
Быстрое развёртывание и простота эксплуатации.
Высокий уровень безопасности и соответствие требованиям ФСТЭК.
Низкие системные требования и возможность использования на устаревшем оборудовании.
Гибкая модель лицензирования и конкурентная стоимость владения.
Заключение
Numa vServer представляет собой надёжное и функциональное решение для создания защищённых виртуальных инфраструктур в условиях импортозамещения. Благодаря своей архитектуре, соответствию требованиям безопасности и широкому функционалу, платформа может стать основой для построения эффективных и безопасных ИТ-систем в различных отраслях.
Интеграция VMware vCenter Server с Active Directory (AD) позволяет централизовать управление учетными записями и упростить администрирование доступа. Вместо локальной базы пользователей vCenter можно использовать доменную инфраструктуру AD или другой LDAP-сервис как единый источник аутентификации. Это означает, что администраторы vSphere смогут применять те же учетные записи и группы, что и для остальных ресурсов сети, для доступа к объектам vSphere.
Компания VMware недавно выпустила обновленную версию средства для виртуализации и агрегации сетей NSX 4.2.2, которое предлагает множество новых функций, обеспечивая расширенные возможности виртуализованных сетей и безопасности для частных облаков.
Основные улучшения охватывают следующие направления:
Межсетевой экран vDefend представляет новый высокопроизводительный режим Turbo (SCRX), который повышает производительность распределённой IDS/IPS-системы и механизма обнаружения приложений уровня L7 для распределённого межсетевого экрана. Новый механизм инспекции использует детерминированное распределение ресурсов и расширенные конвейеры обработки пакетов в гипервизоре ESXi, обеспечивая прирост производительности при значительно меньшем потреблении ресурсов памяти и процессора.
Enhanced Data Path (EDP) получил ряд улучшений, включая добавление скрипта, снижающего необходимость ручного вмешательства при включении EDP в кластере, а также улучшения стабильности, совместимости и снижение влияния на операции жизненного цикла.
В этом выпуске VMware NSX включает улучшения платформы Edge, в том числе новую опцию повторного развертывания и улучшенную документацию по API мониторинга Edge.
Скрипт Certificate Analyzer Resolver (CARR) теперь поддерживает проверку сертификатов Compute Manager (vCenter). Он выполняет проверку целостности и восстановление самоподписных сертификатов NSX, а также может заменять сертификаты, срок действия которых истёк или скоро истечёт.
Среди новых улучшений безопасности платформы — предопределённая роль Cloud Admin Partner, увеличение числа поддерживаемых групп LDAP и Active Directory, а также поддержка стандарта FIPS 140-3.
Сетевые возможности
1. Сеть канального уровня (Layer 2 Networking)
Появился скрипт автоматизации включения режима коммутатора EDP для VCF 5.2.x (NSX 4.2.2). В состав NSX Manager добавлен скрипт enable_uens, предназначенный для сокращения ручных действий при включении режима Enhanced Data Path Standard на кластере. Скрипт последовательно выполняет следующие шаги на хостах:
Переводит хост в режим обслуживания
Обновляет режим коммутатора на EDP
Выводит хост из режима обслуживания
Синхронизирует изменения с Transport Node Profile кластера
Он выполняется из той же директории и применяется к одному кластеру за раз, требуя входных данных из JSON-файла. Подробные инструкции приведены в файле readme скрипта.
Скрипт особенно полезен для релизов NSX 4.x, так как смена режима передачи данных на EDP Standard через настройки Transport Node Profile вызывает немедленные изменения на хостах ESXi, что может привести к сетевому простою на несколько секунд на каждом хосте. Метод "Enabling EDP Standard in Active Environments" снижает простой, но требует ручного вмешательства на каждом хосте, что при масштабных развертываниях становится крайне трудоёмким из-за шагов с режимом обслуживания.
2. Повышение надёжности EDP Standard в рамках долгосрочной поддержки (LTS)
NSX 4.2.2 рекомендуется как основная версия для использования Enhanced Data Path во всех развертываниях VMware Cloud Foundation и типах рабочих доменов, включая кластеры NSX Edge и общие вычислительные кластеры (VI Workload Domains).
EDP рекомендован для достижения максимальной производительности обработки сетевого трафика и минимизации затрат ресурсов на сетевую обработку. В этом релизе реализованы улучшения стабильности и совместимости, благодаря чему он рекомендован в качестве версии с долгосрочной поддержкой (LTS) для NSX 4.2.
Основные улучшения надёжности в NSX 4.2.2:
Повышена производительность EDP при масштабных развертываниях.
Улучшена работа EDP в средах на базе vSAN.
Повышена производительность EDP при использовании распределённого межсетевого экрана.
Расширена совместимость с сетевыми адаптерами через механизм driver shimming.
Совместимость EDP с контейнерными платформами (NCP, Antrea).
Повышена доступность (uptime) канала данных EDP Standard при операциях жизненного цикла — время переключения сокращено с десятков секунд до менее чем 3 секунд.
В пользовательском интерфейсе добавлена кнопка Redeploy Edge, позволяющая легко и быстро повторно развернуть узел Edge. Эта операция запускает соответствующий API, как указано в документации: NSX Edge VM Redeploy API.
Это улучшение упрощает процесс повторного развертывания, снижает операционные издержки и улучшает пользовательский опыт, предоставляя возможность настройки параметров Edge при повторном запуске.
Обновлённая документация по API мониторинга NSX Edge теперь предоставляет более понятные и подробные инструкции. В ней содержатся:
Подробные объяснения всех соответствующих API-вызовов с примерами запросов и ответов.
Полные описания возвращаемых мониторинговых данных, включая поэлементную расшифровку каждого поля.
Глубокое разъяснение всех доступных метрик: что они обозначают, как рассчитываются и как их интерпретировать в реальных сценариях.
Безопасность
1. Межсетевой экран (Firewall)
Распределённый межсетевой экран (Distributed Firewall) использует новый высокопроизводительный режим Turbo (SCRX) для фильтрации приложений уровня L7.
NSX Manager теперь поддерживает большее количество сервисов межсетевого экрана для экземпляров класса Extra Large. Подробности см. в разделе Configuration Maximums.
Группировка в межсетевом экране поддерживает большее число активных участников как для конфигураций Large, так и Extra Large. Подробнее — в Configuration Maximums.
2. IDS/IPS
Распределённая система IDS/IPS демонстрирует значительный прирост производительности благодаря новому высокопроизводительному движку Turbo (SCRX). При использовании нового движка возможно достичь скорости анализа трафика до 9 Гбит/с в зависимости от профиля трафика на хосте ESXi.
Показатели производительности и другие операционные метрики Distributed IDS/IPS доступны в реальном времени через Security Services Platform (SSP).
Внимание: новый движок SCRX предъявляет строгие требования к совместимости с версией ESXi, а также имеет особые условия для установки/обновления. См. раздел Getting Started и выполните Turbo Mode Compatibility Pre-Check Script для проверки среды. Дополнительную информацию можно найти в базе знаний (KB) — статья 396277.
Настоятельно рекомендуется запускать скрипт CARR перед обновлением NSX Manager. Цель — убедиться, что срок действия сертификатов Transport Node (TN) не истекает в течение 825 дней. Если срок действия сертификата TN меньше этого значения, скрипт можно повторно запустить для его замены. См. статью Broadcom KB 369034.
2. Управление доступом (RBAC)
Добавлена новая предопределённая роль Cloud Partner Admin — специально для облачных партнёров, которым необходим доступ к функциям сетей и безопасности, но при этом нужно исключить доступ к просмотру лицензий NSX.
3. Аутентификация через LDAP
Увеличено максимальное число поддерживаемых групп LDAP и Active Directory — с 20 до 500.
4. Сертификация платформы
Поддержка стандарта FIPS 140-3: NSX 4.2.2 теперь использует криптографические модули, соответствующие требованиям FIPS 140-3 (Federal Information Processing Standards). NSX работает в режиме соответствия FIPS по умолчанию во всех развертываниях. Подтверждение соответствия стандарту FIPS 140-3 гарантирует, что NSX использует актуальные криптомодули для надёжной защиты рабочих нагрузок. Дополнительная информация о модулях доступна по ссылке в оригинальной документации.
Компания Broadcom официально объявила о запуске средства измерения использования облачных ресурсов VMware Cloud Foundation версии 9.0 (VCF Usage Meter), ранее известного как VMware vCloud Usage Meter. Оно доступно с 7 мая 2025 года.
Обзор VCF Usage Meter
VCF Usage Meter — это виртуальный модуль, развёртываемый на экземпляре сервера vCenter в рамках частного облака VMware Cloud Foundation. Он играет ключевую роль в измерении потребления основных продуктов в средах VMware Cloud Service Provider (VCSP) и создании отчётов об использовании. Этот релиз включает новые возможности измерения, улучшенную безопасность и поддержку VCF 9.0 (после его предстоящего релиза).
VCF Usage Meter 9.0 является обязательным инструментом для всех поставщиков облачных услуг VMware. Он необходим для измерения использования ядер CPU в соответствии с требованиями программы.
Провайдеры VCSP обязаны обновиться до версии VCF Usage Meter 9.0 в течение 90 дней с момента релиза (General Availability). Если обновление не будет завершено в этот срок, Broadcom перестанет принимать данные об использовании со старых версий Usage Meter, а авторизация поставщика как VCSP будет отозвана.
В таких случаях среда партнёра будет помечена как не соответствующая требованиям программы VCSP, что может привести к несоответствиям в выставлении счетов, ограничению поддержки, исключению из участия в программе и другим связанным последствиям.
Чтобы обеспечить бесперебойную работу и соответствие требованиям, рекомендуется начать планирование обновления как можно раньше, чтобы уложиться в 90-дневный срок. У провайдеров есть время до 5 августа 2025 года, чтобы обновить текущие экземпляры Usage Meter до новой версии VCF Usage Meter 9.0 и сохранить соответствие требованиям.
Новые функции, улучшения и обзор
1. Поддержка измерения метрик VCF 9.0
VCF Usage Meter 9.0 полностью готов к измерению использования для предстоящей версии VMware Cloud Foundation 9 — важного этапа на пути к единой и современной платформе частного облака.
Чтобы обеспечить плавный переход для поставщиков облачных услуг VMware (VCSP), процесс измерения в VCF 9.0 максимально схож с предыдущими версиями. Начать работу просто: добавьте конечные точки vCenter в VCF Usage Meter, и измерение начнётся автоматически.
Все знакомые инструменты отчетности — Hourly Usage Report (HUR), Virtual Machine History Report (VMHR) и потоки данных для расчета использования — продолжают предоставлять необходимые вам данные. Эти отчёты полностью интегрированы с консолью VMware Cloud Foundation Business Services (VCF Business Services Console) и поддерживают развертывания VCF 9.0.
Обратите внимание, что лицензионные ключи будут заменены на бесключевым механизмом, активируемым через облако права (entitlements), что упрощает активацию и повышает точность расчётов.
2. Новая аутентификация на основе OAuth-приложения
Broadcom добавила новый уровень безопасности для загрузки данных об использовании в консоль VCF Business Services — авторизация на основе OAuth-приложения для VCF Usage Meter 9.0. Хотя загрузка данных всегда защищалась через HTTPS (и продолжит работать), OAuth позволяет пользователю авторизовать консоль VCF Business Services для доступа к данным измерений, хранящимся в VCF Usage Meter 9.0, без передачи самих учётных данных.
С выходом VCF Usage Meter 9.0 регистрация в консоли VCF Business Services автоматически создаёт выделенное OAuth-приложение и генерирует уникальный токен для каждого экземпляра Usage Meter. Поставщики услуг (VCSP) используют этот токен при установке или обновлении апплаенса VCF Usage Meter 9.0. После установки Usage Meter безопасно обменивается данными с консолью через этот токен OAuth.
Этот шаг обязателен для соответствия требованиям безопасности и не может быть обойдён. VCSP могут управлять своими OAuth-токенами напрямую через консоль VCF Business Services — в том числе отзывать доступ и обновлять токены в соответствии с внутренними политиками безопасности.
Все эти операции доступны в формате самообслуживания через RESTful API. Подробности см. в документации по API.
3. Поддержка измерения и расчёта превышения по vDefend Add-On
Чтобы помочь VCSP в полной мере использовать гибкость модели потребления, Broadcom добавила поддержку измерения и расчёта превышений (overage billing) для дополнений VMware vDefend, которые теперь интегрированы в VCF Usage Meter 9.0.
Как и для основных продуктов VCF, VCSP теперь могут легко использовать следующие дополнения vDefend Firewall по модели с фиксированным контрактом и с учётом превышения:
VMware vDefend Firewall
VMware vDefend Firewall с расширенной защитой от угроз (Advanced Threat Prevention)
Чтобы начать измерение, просто добавьте конечную точку NSX Manager в VCF Usage Meter 9.0. Использование будет отслеживаться и управляться через Hourly Usage Report, доступный в консоли VCF Business Services. Нажмите здесь для получения подробной информации о метеринге vDefend Firewall.
Уже являетесь VCSP с активным контрактом на vDefend? Вы можете немедленно начать измерение, обновившись до VCF Usage Meter 9.0. Убедитесь, что вы используете лицензионные ключи Broadcom, выданные через портал Broadcom Consumption — они необходимы для точного измерения и корректного биллинга.
4. Важное уведомление: соответствие требованиям и точность расчётов с NSX
Устаревшие лицензионные ключи VMware NSX больше не поддерживаются для измерения. Их дальнейшее использование может привести к ошибкам в расчетах и несоответствию требованиям программы VCSP. Также устаревшие версии NSX и просроченные лицензии могут непреднамеренно активировать измерение vDefend из-за существующих конфигураций сетевого экрана.
Чтобы избежать неожиданных начислений и обеспечить корректное измерение в VCF Usage Meter 9.0, настоятельно рекомендуется проверить окружение NSX перед обновлением.
5. Поддержка новой консоли VCF Business Services для управления Usage Meter
Важное обновление для VCSP: управление VCF Usage Meter теперь осуществляется через новую консоль VCF Business Services — единую платформу, созданную для упрощения операций и взаимодействия с поддержкой.
Консоль VCF Business Services тесно интегрирована с экосистемой поддержки Broadcom и предлагает:
Единый вход (SSO) во все сервисы Broadcom
Упрощённое управление пользователями и доступом через Broadcom Site ID
Плавную интеграцию между сайтом и клиентом (tenant), упрощающую управление правами и операциями
6. Новый отчёт Customer Hourly Usage Report (CHUR)
В рамках этого перехода все существующие учётные записи и зарегистрированные конфигурации VCF Usage Meter из текущей консоли VMware Cloud Services будут перенесены в новую платформу VCF Business Services. Сохранятся знакомые процессы регистрации, генерации отчётов и использования API-интеграций — теперь с улучшенным и более масштабируемым интерфейсом.
Почему версия Usage Meter 9.0 так важна для VCSP?
Важно подчеркнуть, что VCF Usage Meter 9.0 полностью поддерживает измерение использования ресурсов (Core Utilization) в частном облаке VMware Cloud Foundation с использованием лицензионных ключей Broadcom — его использование абсолютно необходимо для корректного измерения среды. Поэтому критически важно либо обновить ваш текущий экземпляр Usage Meter до версии VCF Usage Meter 9.0, либо развернуть новый экземпляр, работающий на этой версии.
Для соблюдения требований у вас есть 90 дней — до 5 августа 2025 года, чтобы обновить все экземпляры Usage Meter до новой версии VCF Usage Meter 9.0.
Другие важные обновления
1. Миграция в консоль VCF Business Services
Одновременно с выходом VCF Usage Meter 9.0 в статус General Availability (GA), станет доступной новая консоль VCF Business Services. Более подробную информацию можно найти на странице портала VCSP, в разделе "VCF Cloud Console Migration Updates".
Пожалуйста, ознакомьтесь со следующими материалами:
Примечание: если у вас возникают проблемы с доступом, войдите в партнёрский портал Broadcom через вашу учётную запись OKTA, затем перейдите в "Learning@Broadcom" и выполните поиск по запросу "Cloud Console training for VCSP Pinnacle and Premier Partners", как показано на скриншоте ниже:
Обновление лимита на количество ядер (Core Cap Update)
Начиная с 12 мая 2025 года, для всех поставщиков облачных услуг VMware (VCSP) количество загружаемых лицензионных ключей будет ограничено максимумом в 200% от заявленного объема (commit), чтобы сохранить гибкость бизнес-моделей и возможность сверхнормативного использования (overage).
Пример: если вы законтрактованы на 10 000 ядер VMware Cloud Foundation (VCF), то с 12 мая общее количество созданных лицензионных ключей по данному обязательству будет ограничено 20 000 ядрами VCF.
Это изменение не повлияет на уже сгенерированные ядра, но будет препятствовать генерации дополнительных лицензий, если установленный лимит по конкретному контракту достигнут.
Путь обновления до VCF Usage Meter v9.0
Проверьте возможные пути обновления до VCF Usage Meter 9.0 по этой ссылке.
Другие полезные ресурсы
Чтобы узнать больше о VCF Usage Meter 9.0, воспользуйтесь следующими материалами:
VMware Cloud Foundation (VCF) — это полноценное решение для частного облака, которое интегрирует программно-определяемые вычисления, хранилища данных и сетевые ресурсы вместе с инструментами автоматизации и управления облаком. Компонент VCF — VMware Cloud Foundation Operations (VCF Operations) — предоставляет организациям возможность видеть свою инфраструктуру, оптимизировать планирование емкости и ресурсов, отслеживать производительность и контролировать состояние инфраструктуры.
Для поставщиков облачных сервисов VMware Cloud Service Providers (VCSP) крайне важно сохранять финансовую прозрачность перед своими клиентами, одновременно оптимизируя операционные расходы. VMware Chargeback, который теперь является частью VCF Operations (ранее известного как VMware Aria Operations), позволяет провайдерам VCSP распределять и возмещать стоимость облачных ресурсов и услуг между пользователями или подразделениями, которые их используют. VMware Cloud Director (VCD) помогает VCSP управлять несколькими арендаторами на одной и той же инфраструктуре. Chargeback использует эту структуру на уровне арендаторов для точного учета затрат.
О продукте VMware Chargeback
VMware Chargeback разработан, чтобы помочь провайдерам VCSP отслеживать использование ресурсов и применять точные модели расчета стоимости для выставления счетов арендаторам. Он бесшовно интегрируется с VCD и другими многопользовательскими средами, обеспечивая точную финансовую отчетность. Chargeback помогает управлять затратами на ИТ-ресурсы и выставлять счета для различных подразделений, бизнес-единиц и клиентов. Благодаря поддержке мощных инструментов и четко определенных политик, он обеспечивает прозрачное, справедливое и легко понимаемое управление расходами на облачные сервисы.
Ключевые возможности:
Автоматизированное распределение затрат: Chargeback назначает стоимость на основе фактического потребления вычислительных ресурсов, хранилищ данных и сетевых ресурсов каждым арендатором, позволяя им отслеживать свои ИТ-расходы и подтверждать начисления через анализ использования. Отчеты можно настроить для отображения затрат на виртуальную машину, приложение или услугу.
Поддержка многопользовательских сред: VCSP могут предлагать своим арендаторам различные модели биллинга, что усложняет процесс отслеживания, распределения и выставления счетов. Chargeback помогает согласовать разные ценовые модели и обеспечить корректное распределение затрат на уровне арендаторов в VMware Cloud Director. Администраторы могут включить для арендаторов дэшборды самообслуживания, где те будут видеть только свои виртуальные машины, рабочие нагрузки и компоненты инфраструктуры.
Гибкие модели ценообразования: Chargeback поддерживает фиксированную, переменную и многоуровневую структуры цен:
Фиксированная модель: стоимость заранее определена и не зависит от объема использования ресурсов, что обеспечивает предсказуемость бюджета.
Переменная модель: стоимость зависит от фактического использования ресурсов, стимулируя эффективное потребление.
Многоуровневая модель: предполагает скидки при увеличении потребления ресурсов, что выгодно при масштабировании.
Пользовательские отчеты и панели: Chargeback позволяет использовать готовые шаблоны или создавать собственные отчеты для отслеживания нужных метрик, а также настраивать их плановое создание. В реальном времени доступны визуальные дэшборды с графиками, диаграммами, тепловыми картами и т.д., что помогает выявлять тенденции в данных. Можно настраивать оповещения на основе пороговых значений для отдельных арендаторов. Поддерживается мониторинг на уровне кластера с агрегированным использованием ресурсов. Среди доступных инструментов — дэшборды памяти, хранилищ, использования сети, виртуальных машин, сводные дэшборды арендаторов и другие.
Интеграция со сторонними системами: Chargeback интегрируется с внешними платформами биллинга, такими как SAP, Oracle и другими, через API для автоматизации создания биллинговых тикетов и счетов. Организации могут извлекать данные из Chargeback для своих систем аналитики или передавать туда запросы. Пакеты управления позволяют интегрировать внешние среды вроде AWS, Azure и другие, чтобы активировать возможности Chargeback в рамках VCF Operations и отслеживать затраты.
Основные моменты интеграции Chargeback
Оптимизация настроек управления арендаторами: VCSP должны убедиться, что плагин Aria Operations включен для их арендаторов. Он обеспечивает видимость операций в облаке и дает арендаторам инструменты для мониторинга, управления и оптимизации своей деятельности. После активации появляется возможность настраивать пользовательский опыт арендаторов.
Тонкая настройка пользовательского опыта: администраторы могут настраивать представление данных и доступные метрики для арендаторов, чтобы показывать только релевантную информацию и минимизировать «шум». Они также управляют доступом к страницам и задают периоды хранения данных для соблюдения политик хранения.
Управление уведомлениями для арендаторов: функция настройки электронной почты позволяет VCSP создавать уведомления, оповещения и отчеты для арендаторов.
Упрощенное управление политиками: инструмент создания политик облегчает разработку и управление стратегиями ценообразования, делая биллинг арендаторов эффективным и точным. VCSP могут интуитивно определять и адаптировать политики ценообразования в зависимости от своих целей и ожиданий клиентов.
Автоматизация биллинга для финансовой точности: автоматизация процессов выставления счетов повышает точность, согласованность и эффективность расчетов. Счета могут отправляться по установленному расписанию, которое стоит регулярно пересматривать в зависимости от изменяющихся потребностей арендаторов.
Оповещения и отчеты в реальном времени: VCSP могут задавать условия для срабатывания оповещений, привязывать их к профилям арендаторов, определять каналы оповещения (email, SMS) и частоту отправки. Отчеты помогают делиться аналитикой VCD с арендаторами.
Анализ затрат для сравнительного ценообразования: пользователи могут сравнивать метрики расходов VMware Cloud между объектами, группами, приложениями и арендаторами, визуализировать данные в виде графиков и таблиц, а также сохранять результаты для дальнейшего использования.
Почему VMware Chargeback необходим VCSP
Для поставщиков услуг инфраструктура VMware Cloud Director предлагает полный набор инструментов, включая возможности настройки интеграции, управления доступом арендаторов, настройки входящих/исходящих писем арендаторов и отправки отчетов и уведомлений.
Интегрируя ключевые платформы, такие как vCenter, VCD, Cloud Director Availability и NSX, поставщики услуг могут создать целостную среду, которая упрощает и повышает точность процедур расчёта затрат (chargeback). VCSP могут использовать пакеты управления как для этих платформ, так и для других решений, соответствующих их облачной инфраструктуре управления.
1. Оптимизированное возмещение затрат и повышение прибыльности
Одна из главных задач для VCSP — обеспечить, чтобы все инфраструктурные и операционные расходы были корректно распределены между клиентами. VMware Chargeback устраняет потери дохода, предоставляя точную и автоматизированную систему распределения затрат, что обеспечивает прибыльность. Это позволяет избежать ошибок, связанных с ручным отслеживанием, и разделять затраты по отделам или клиентам. Облачные провайдеры могут дополнительно монетизировать свои предложения, используя VMware Chargeback для взимания повышенных ставок за премиальные ресурсы, такие как сети с низкой задержкой или выделенные процессорные мощности (модель ценообразования на основе выделения ресурсов).
2. Прозрачность и доверие со стороны клиентов
Клиенты ожидают получать подробную информацию о своем использовании ресурсов и начисленных платежах. VMware Chargeback предоставляет детализированные отчеты, показывающие, сколько именно стоит каждый используемый ресурс, что помогает VCSP обосновывать начисления и укреплять доверие клиентов, устраняя скрытые расходы и снижая количество споров по счетам. Арендаторы получают доступ к данным биллинга в реальном времени, что позволяет избежать неожиданных расходов. Так как оплата производится на основе фактического использования ресурсов, это способствует сокращению избыточных затрат, оптимизации рабочих нагрузок и помогает клиентам избегать расходов на неиспользуемые ресурсы.
3. Операционная эффективность и автоматизация
Ручное отслеживание затрат требует много времени и подвержено ошибкам. VMware Chargeback автоматизирует измерение использования ресурсов, снижая административную нагрузку и позволяя поставщикам услуг сосредоточиться на предоставлении дополнительных сервисов с высокой добавленной стоимостью. Это также упрощает процесс выставления счетов для большого количества клиентов. Поставщики могут более точно планировать емкость ресурсов, анализируя исторические данные из отчетов.
4. Мониторинг за пределами виртуальных машин
Пользователи могут отслеживать производительность на уровне приложений, анализируя время отклика API, нагрузку на веб-серверы и зависимости приложений, чтобы увидеть, как рабочие нагрузки взаимодействуют с VCF Operations. Также доступен мониторинг Kubernetes и контейнеров — можно отслеживать состояние узлов, сервисов и кластеров. Мониторинг сети и безопасности помогает анализировать микро-сегментацию и отслеживать сетевой трафик, задержки и другие параметры для каждого арендатора. Такая полноуровневая наблюдаемость крайне важна для VCSP при планировании и расчете затрат.
5. Поддержка частного облака
Для VCSP, предоставляющих решения частного облака, VMware Chargeback расширяет возможности частного облака, обеспечивая единое распределение затрат в таких средах, а также финансовую прозрачность и отчетность при внутреннем биллинге.
Заключение
Прозрачность облачных затрат имеет решающее значение для любой организации, а интеграция системы распределения затрат в бизнес-модель VCSP становится важнейшим фактором масштабируемости и роста. Это позволяет клиентам гибко регулировать потребление ресурсов в зависимости от спроса и платить только за фактическое использование. Пользователи могут отслеживать производительность, затраты и емкость ресурсов, что помогает им оптимизировать инвестиции в инфраструктуру. Chargeback позволяет VCSP удовлетворять потребности широкой клиентской базы, предлагая различные модели ценообразования. Арендаторы получают доступ к самообслуживаемым дэшбордам, отчетам и оповещениям, что улучшает их пользовательский опыт. Грамотно реализованная система распределения затрат становится конкурентным преимуществом для VCSP.
Узнать больше о продукте VMware Chargeback можно здесь.
В видеоролике ниже рассматривается то, как включить Virtualization-Based Security (VBS) в гостевых операционных системах Windows, работающих в среде VMware Cloud Foundation и vSphere:
Что такое Virtualization-Based Security (VBS)?
VBS — это технология безопасности от Microsoft, использующая возможности аппаратной виртуализации и изоляции для создания защищённой области памяти. Она используется для защиты критически важных компонентов операционной системы, таких как Credential Guard и Device Guard.
Предварительные требования
Перед тем как включить VBS, необходимо убедиться в выполнении следующих условий:
Active Directory Domain Controller
Необходим для настройки групповой политики. В демонстрации он уже создан, но пока выключен.
Загрузка через UEFI (EFI)
Виртуальная машина должна использовать загрузку через UEFI, а не через BIOS (legacy mode).
Secure Boot
Желательно включить Secure Boot — это обеспечивает дополнительную защиту от вредоносных программ на стадии загрузки.
Модуль TPM (Trusted Platform Module)
Не обязателен, но настоятельно рекомендуется. Большинство руководств по безопасности требуют его наличия.
Настройка VBS в VMware
Перейдите к параметрам виртуальной машины в Edit Settings.
Убедитесь, что:
Используется UEFI и включен Secure Boot.
Включена опция "Virtualization-based security" в VM Options.
Виртуализация ввода-вывода (IO MMU) и аппаратная виртуализация будут активированы после перезагрузки.
Важно: Если переключаться с legacy BIOS на EFI, ОС может перестать загружаться — будьте осторожны.
Настройка VBS внутри Windows
После включения параметров на уровне гипервизора нужно активировать VBS в самой Windows:
Turn on Virtualization Based Security – активировать.
Secure Boot and DMA Protection – да.
Virtualization-based protection of Code Integrity – включить с UEFI Lock.
Credential Guard – включить.
Secure Launch Configuration – включить.
Примечание: Если вы настраиваете контроллер домена, обратите внимание, что Credential Guard не защищает базу данных AD, но защищает остальную ОС.
Перезагрузите виртуальную машину.
Проверка работоспособности VBS
После перезагрузки:
Откройте System Information и убедитесь, что:
Virtualization Based Security включена.
MA Protection работает.
redential Guard активен.
В Windows Security проверьте:
Включена ли Memory Integrity.
Активна ли защита от вмешательства (Tamper Protection).
Заключение
Теперь у вас есть полностью защищённая Windows-гостевая ОС с включённой Virtualization-Based Security, Credential Guard и другими функциями. Это отличный способ повысить уровень безопасности в вашей инфраструктуре VMware.
Для получения дополнительной информации смотрите ссылки под видео.
Таги: VMware, vSphere, Security, VMachines, Windows
Недавно было объявлено о доступности VMware vSphere Kubernetes Service (VKS) 3.3 (ранее известного как решение VMware Tanzu Kubernetes Grid (TKG) Service), а также о выпуске vSphere Kubernetes release (VKr) 1.32, ранее называвшегося Tanzu Kubernetes release. В этом выпуске представлены важные функции и улучшения, направленные на повышение безопасности, масштабируемости и управления кластерами.
Поддержка актуального релиза Kubernetes 1.32
С выпуском VKS 3.3 теперь возможно развертывание рабочих кластеров на базе VKr 1.32, основанного на последнем минорном выпуске Kubernetes 1.32. Использование последних версий Kubernetes обеспечивает безопасность, высокую производительность и совместимость с современными приложениями. vSphere Kubernetes release 1.32 обеспечивает повышение эффективности, безопасности и гибкости рабочих нагрузок.
Гибкость активации режима FIPS на уровне ОС
Данный выпуск вводит новую возможность настройки режима FIPS на уровне операционной системы, гарантируя использование только одобренных FIPS криптографических модулей. Администраторы могут самостоятельно решить, активировать ли режим FIPS для кластеров на Linux и Windows. Для активации функции необходимо настроить переменную класса кластера 'osConfiguration'. Для включения данной функции в Ubuntu-версии vSphere Kubernetes может потребоваться подписка Ubuntu Pro. Подробная информация представлена в документации.
Если ваша организация работает в регулируемой отрасли (государственные учреждения, финансы, здравоохранение и др.), соответствие стандартам FIPS необходимо для соблюдения требований безопасности и снижения рисков несоответствия.
Переход на Cluster API
Как было объявлено в документации к выпуску VKS 3.2, API TanzuKubernetesCluster будет удалён не ранее июня 2025 года. VKS 3.3 вводит упрощённый механизм миграции кластеров с TKC на Cluster API для развертывания и настройки рабочих кластеров. Переход на Cluster API обеспечивает лучшую автоматизацию и будущую совместимость. Рекомендуется заранее планировать переход на Cluster API, чтобы избежать сбоев после удаления TKC API.
Другие важные улучшения
Интеграция узлов Windows с Active Directory (поддержка gMSA) – начиная с VKS 3.3, вы можете подключать узлы Windows к локальной службе Active Directory с использованием учётных записей группового управления (Group Managed Service Accounts, gMSA) для безопасной аутентификации. Можно автоматизировать подключение узлов Windows к домену Active Directory в организационных подразделениях и добавлять их в группу безопасности, управляющую доступом к gMSA. Это упрощает интеграцию рабочих нагрузок Kubernetes на базе Windows в предприятиях, использующих Active Directory, повышая безопасность и операционную эффективность. Подробности можно найти в документации.
Автомасштабирование кластеров в обе стороны – VKS 3.3 позволяет масштабировать кластеры от нуля до любого количества рабочих узлов при использовании VKr версии 1.31.4 и новее. Ранее эта функция была недоступна со времен появления Cluster Autoscaler в vSphere 8.0 U3. Также это способствует экономии средств и оптимизации ресурсов, позволяя динамически масштабировать рабочие нагрузки до нуля в неиспользуемый период и эффективно справляться с сезонными всплесками активности.
Механизмы для упрощения обновления (Guard Rails) - обновления через несколько версий могут быть затруднены, особенно с устаревшими ресурсами. В версии VKr 1.31.1 в Antrea 2.1 некоторые CRD были объявлены устаревшими и должны быть заменены на новые версии.
Обновление до VKr 1.31.1 – перед обновлением обязательно выполнить минимальные ручные инструкции, указанные в Release Notes 1.31.1, иначе обновление может завершиться неудачно.
Обновление до VKr 1.31.4 – При обновлении до версии VKr 1.31.4 устаревшие CRD Antrea автоматически заменяются новыми версиями, поэтому ручные действия не требуются.
В VKS 3.3 встроены механизмы защиты от потенциальных ошибок при обновлении. Если рабочий кластер использует Kubernetes версии 1.30.x и обновлен до VKS 3.3, обновление до Kubernetes версии 1.31.1 заблокировано. Вместо этого рекомендуется сразу перейти на версию 1.31.4, которая не требует ручных действий. Если рабочий кластер уже на версии VKr 1.31.1, то обновление до VKS 3.3 заблокировано до предварительного обновления до VKr 1.31.4.
Заключение
vSphere Kubernetes Service 3.3 предлагает повышенную безопасность, улучшенную масштабируемость, оптимизацию расходов и усовершенствованное управление жизненным циклом кластеров для оптимизации Kubernetes-сред клиентов. О работе продукта также можно почитать вот эту полезную статью.
В январе 2025 года компания VMware опубликовала технический документ под названием «Performance Tuning for Latency-Sensitive Workloads: VMware vSphere 8». Этот документ предоставляет рекомендации по оптимизации производительности для рабочих нагрузок, критичных к задержкам, в среде VMware vSphere 8.
Документ охватывает различные аспекты конфигурации, включая требования к базовой инфраструктуре, настройки хоста, виртуальных машин, сетевые аспекты, а также оптимизацию операционной системы и приложений. В разделе «Host considerations» обсуждаются такие темы, как изменение настроек BIOS на физическом сервере, отключение EVC, управление vMotion и DRS, а также настройка продвинутых параметров, таких как отключение action affinity и открытие кольцевых буферов.
В разделе «VM considerations» рассматриваются рекомендации по оптимальному выделению ресурсов виртуальным машинам, использованию актуальных версий виртуального оборудования, настройке vTopology, отключению функции hot-add, активации параметра чувствительности к задержкам для каждой ВМ, а также использовании сетевого адаптера VMXNET3. Кроме того, обсуждается балансировка потоков передачи и приема данных, привязка потоков передачи к определенным ядрам, ассоциация ВМ с конкретными NUMA-нодами и использование технологий SR-IOV или DirectPath I/O при необходимости.
Раздел о сетевых настройках акцентирует внимание на использовании улучшенного пути передачи данных для NFV-нагрузок и разгрузке сервисов vSphere на DPU (Data Processing Units), также известных как SmartNICs.
Наконец, в разделе, посвященном настройке гостевой ОС и приложений, приводятся рекомендации по оптимизации производительности на уровне операционной системы и приложений, работающих внутри виртуальных машин.
Облачные технологии постоянно развиваются, и VMware Cloud Director (VCD) продолжает совершенствоваться с новыми обновлениями, которые укрепляют безопасность, упрощают управление ресурсами и предоставляют пользователям больше возможностей контроля. VMware недавно объявила, что VMware Cloud Director 10.6.1 теперь доступен в составе VMware Cloud Foundation (VCF), начиная с 31 января 2025 года.
Основные улучшения в этом релизе
Интеллектуальное размещение ВМ с учетом гостевой ОС
Теперь вы можете легко размещать виртуальные машины на определенных хостах или кластерах в зависимости от их гостевой операционной системы. Эта функция позволяет администраторам создавать группы ВМ для конкретных типов ОС, обеспечивая правильное распределение и соответствие требованиям всех арендаторов. Кроме того, это помогает организациям соответствовать требованиям лицензирования Microsoft и других поставщиков, упрощая управление лицензиями и оптимизируя использование ресурсов.
Применение:
Автоматическое применение правил гарантирует, что ВМ всегда размещаются в назначенных группах.
Простая реконфигурация: существующие ВМ автоматически примут это правило при следующем изменении конфигурации, например при перезагрузке или редактировании ВМ.
Улучшенное распределение нагрузки и упрощенное управление мультиарендами.
Контроль безопасности API-токенов
Безопасность имеет первостепенное значение, и теперь VCD включает возможность принудительного истечения срока действия API-токенов. Если необходимо немедленно отозвать токен — по соображениям безопасности или в связи с изменениями в управлении, администраторы могут сделать это мгновенно. Это обеспечивает более проактивный подход к управлению доступом к API и защите облачных сред.
Применение:
Мгновенный отзыв токенов для повышения уровня безопасности.
Повышенный контроль администраторов над аутентификацией и управлением доступом.
Гибкое управление IP-адресами для субпровайдеров и управляемых организаций
Управлять IP-адресами стало проще! Теперь VMware Cloud Director позволяет настраивать индивидуальные периоды хранения IP-адресов как на уровне субпровайдеров, так и на уровне управляемых организаций. Это означает, что IP-адреса могут сохраняться даже после удаления ВМ или сетевых интерфейсов (NIC), независимо от способа их назначения (Static Pool, Static Manual или DHCP).
Применение:
Настраиваемое хранение IP-адресов обеспечивает их сохранность и снижает необходимость повторного выделения.
Конфигурация на основе метаданных позволяет администраторам задавать периоды хранения в соответствии с потребностями организации.
Использование API Manual Reservation для сохранения IP-адресов при повторном развертывании.
Принудительное применение правил межсетевого экрана на шлюзе
Теперь появилась возможность явного включения или отключения принудительного применения правил межсетевого экрана на шлюзе. Этот функционал интегрирован в стек VCF и предоставляет полный обзор статуса применения правил на межсетевых экранах уровней T1 и T0. Администраторы арендаторов и субарендаторов могут просматривать и изменять настройки по умолчанию, обеспечивая соответствие политике безопасности организации.
Применение:
Полная прозрачность статуса межсетевого экрана.
Административный контроль для включения или отключения правил при необходимости.
Stateful сетевой экран и настройка кластеров Edge
Администраторы провайдеров теперь могут более детально управлять службой Stateful сетевого экрана, встроенной в стек VCF. В этом обновлении они могут запрещать арендаторам добавлять правила на T1, T0 и vApps, если безопасность ANS не включена. Кроме того, новая опция конфигурации для кластеров Edge позволяет провайдерам включать или отключать сетевые экраны по мере необходимости.
Применение:
Детализированный контроль правил сетевого экрана обеспечивает соответствие требованиям безопасности.
Гибкость в управлении сетевой безопасностью на уровне кластеров Edge.
Кастомные пользовательские профили сегментов
можно расшарить
Теперь провайдеры услуг могут делиться пользовательскими профилями сегментов с организациями-арендаторами, что упрощает стандартизацию сетевых политик среди нескольких арендаторов.
Применение:
Улучшенное взаимодействие между провайдерами и арендаторами.
Единые сетевые конфигурации для нескольких организаций.
Поддержка IPv6 для прозрачной балансировки нагрузки
Теперь поддержка IPv6 и VMware Avi Load Balancer Transparent Load Balancing снова доступна! Члены пулов могут видеть IP-адреса исходных клиентов, что повышает уровень видимости и эффективность работы сети. Для включения этой функции необходимо интегрировать VMware Avi Load Balancer с VMware Cloud Director.
Применение:
Легкая поддержка IPv6 для современных сетевых инфраструктур.
Улучшенная балансировка нагрузки с прозрачной маршрутизацией трафика.
Другие улучшения:
Исправленный API обновления кастомных задач – устранена проблема двойного выполнения, теперь API работает корректно с первой попытки.
Исправленный просмотр всех виртуальных датацентров – теперь администраторы могут беспрепятственно переключаться между представлениями без ошибок.
Удалены ссылки на NSX MP API – упрощенный интерфейс без устаревших ссылок.
Обновление VMware Cloud Director 10.6.1 направлено на повышение контроля, улучшение безопасности и расширение сетевых возможностей. Независимо от того, оптимизируете ли вы размещение ВМ, усиливаете защиту API или настраиваете сетевые экраны, эти изменения предоставляют больше возможностей как облачным провайдерам, так и арендаторам.
Обратите внимание, что в будущей версии vSAN в интерфейсе появится опция, которая поможет с операциями, описанными ниже.
Прежде всего, вам нужно проверить, реплицированы ли все данные. В некоторых случаях мы видим, что клиенты фиксируют данные (виртуальные машины) в одном месте без репликации, и эти виртуальные машины будут напрямую затронуты, если весь сайт будет переведен в режим обслуживания. Такие виртуальные машины необходимо выключить, либо нужно убедиться, что они перемещены на работающий узел, если требуется их дальнейшая работа. Обратите внимание, что если вы переключаете режимы "Preferred / Secondary", а множество ВМ привязаны к одному сайту, это может привести к значительному объему трафика синхронизации. Если эти виртуальные машины должны продолжать работать, возможно, стоит пересмотреть решение реплицировать их.
Вот шаги, которые Дункан рекомендует предпринять при переводе сайта в режим обслуживания:
Убедитесь, что vSAN Witness работает и находится в здоровом состоянии (проверьте соответствующие health checks).
Проверьте комплаенс виртуальных машин, которые реплицированы.
Настройте DRS (распределённый планировщик ресурсов) в режим "partially automated" или "manual" вместо "fully automated".
Вручную выполните vMotion всех виртуальных машин с сайта X на сайт Y.
Переведите каждый хост ESXi на сайте X в режим обслуживания с опцией "no data migration".
Выключите все хосты ESXi на сайте X.
Включите DRS снова в режиме "fully automated", чтобы среда на сайте Y оставалась сбалансированной.
Выполните все необходимые работы по обслуживанию.
Включите все хосты ESXi на сайте X.
Выведите каждый хост из режима обслуживания.
Обратите внимание, что виртуальные машины не будут автоматически возвращаться обратно, пока не завершится синхронизация для каждой конкретной виртуальной машины. DRS и vSAN учитывают состояние репликации! Кроме того, если виртуальные машины активно выполняют операции ввода-вывода во время перевода хостов сайта X в режим обслуживания, состояние данных, хранящихся на хостах сайта X, будет различаться. Эта проблема будет решена в будущем с помощью функции "site maintenance", как упоминалось в начале статьи.
Также для информации об обслуживании сети и ISL-соединения растянутого кластера vSAN прочитайте вот эту статью.

 RSS
RSS